| Фаза | Основные решения | Ключевые документы |
|---|---|---|
| Предварительная фаза | Определение организационной модели, архитектурных принципов, инструментальных средств | Организационная модель, каталог архитектурных принципов |
| Фаза A: Видение архитектуры | Разработка высокоуровневого видения возможностей и бизнес-ценностей | Документ видения архитектуры, план управления архитектурным проектом |
| Фаза B: Бизнес-архитектура | Разработка бизнес-архитектуры, поддерживающей видение | Модель бизнес-архитектуры, каталог бизнес-служб |
| Фаза C: Архитектура информационных систем | Разработка архитектуры информационных систем (данных и приложений) | Модели данных, архитектура приложений, каталог систем |
| Фаза D: Технологическая архитектура | Разработка технологической архитектуры | Технологическая архитектура, спецификации инфраструктуры |
| Фаза E: Возможности и решения | Определение разрыва между текущей и целевой архитектурами, идентификация проектов | План миграции, анализ разрывов, план проектов |
| Фаза F: Планирование перехода | Разработка детального плана перехода от текущей к целевой архитектуре | Детальный план перехода, график миграции |
| Фаза G: Управление реализацией | Разработка процессов управления и контроля перехода | План реализации, отчеты о статусе проектов |
| Фаза H: Управление архитектурными изменениями | Установление процессов управления архитектурными изменениями | Процедуры управления изменениями, реестр изменений |
Автор: Денис Матаков
-

Фазы TOGAF 10
-

Чеклист: 100 первых дней на посту СТО
Оценка текущего состояния
- Провести аудит существующей IT-инфраструктуры
- Оценить текущие технологические стеки и инструменты
- Проанализировать бизнес-процессы компании
- Изучить документацию по существующим системам
- Оценить уровень кибербезопасности
- Проверить соответствие нормативным требованиям
- Оценить эффективность текущих IT-операций
- Проанализировать бюджет IT-отдела
- Изучить структуру IT-команды и распределение ролей
- Оценить уровень технической задолженности
Стратегическое планирование
- Определить ключевые цели модернизации
- Разработать дорожную карту цифровой трансформации
- Определить приоритетные направления модернизации
- Установить ключевые показатели эффективности (KPI)
- Создать план управления рисками
- Разработать стратегию обеспечения непрерывности бизнеса
- Определить бюджет на модернизацию
- Создать план коммуникации с заинтересованными сторонами
- Разработать стратегию управления изменениями
- Определить временные рамки для ключевых этапов модернизации
Инфраструктура и архитектура
- Разработать целевую архитектуру предприятия
- Спланировать миграцию в облако (если применимо)
- Оценить потребность в гибридной инфраструктуре
- Внедрить контейнеризацию и оркестрацию (например, Kubernetes)
- Разработать стратегию управления данными
- Внедрить практики DevOps и CI/CD
- Оптимизировать сетевую инфраструктуру
- Внедрить системы мониторинга и логирования
- Разработать стратегию резервного копирования и восстановления
- Оценить необходимость edge computing
Безопасность и соответствие требованиям
- Провести оценку рисков информационной безопасности
- Внедрить многофакторную аутентификацию
- Разработать политику управления доступом
- Внедрить систему управления уязвимостями
- Разработать план реагирования на инциденты
- Обеспечить шифрование данных в состоянии покоя и при передаче
- Внедрить систему обнаружения и предотвращения вторжений (IDS/IPS)
- Провести обучение сотрудников по вопросам кибербезопасности
- Разработать политику безопасности для мобильных устройств
- Обеспечить соответствие требованиям GDPR и других регуляторов
Разработка и инженерия
- Стандартизировать процессы разработки программного обеспечения
- Внедрить практики чистого кода и code review
- Разработать руководства по стилю кода для разных языков программирования
- Внедрить автоматизированное тестирование
- Разработать стратегию управления техническим долгом
- Внедрить систему управления версиями (например, Git)
- Стандартизировать процесс документирования кода и API
- Внедрить практики непрерывной интеграции и развертывания (CI/CD)
- Разработать стратегию микросервисной архитектуры (если применимо)
- Внедрить инструменты статического анализа кода
Данные и аналитика
- Разработать стратегию управления данными
- Внедрить современную платформу для хранения и обработки данных
- Разработать политику управления качеством данных
- Внедрить инструменты бизнес-аналитики и визуализации данных
- Разработать стратегию использования больших данных
- Внедрить практики DataOps
- Разработать стратегию машинного обучения и искусственного интеллекта
- Обеспечить соответствие требованиям к обработке персональных данных
- Внедрить систему управления мастер-данными (MDM)
- Разработать стратегию data governance
Облачные технологии
- Оценить готовность к миграции в облако
- Выбрать подходящего облачного провайдера
- Разработать стратегию миграции в облако
- Внедрить облачную систему управления идентификацией и доступом
- Оптимизировать затраты на облачные ресурсы
- Внедрить практики CloudOps
- Обеспечить соответствие облачной инфраструктуры требованиям безопасности
- Разработать стратегию мультиоблачности (если применимо)
- Внедрить инструменты для мониторинга облачных ресурсов
- Обучить персонал работе с облачными технологиями
Управление проектами и процессами
- Внедрить гибкие методологии разработки (например, Scrum или Kanban)
- Стандартизировать процесс управления проектами
- Внедрить систему управления портфелем проектов
- Разработать процесс приоритизации задач и проектов
- Внедрить инструменты для совместной работы и управления задачами
- Разработать процесс управления изменениями
- Внедрить систему управления знаниями
- Разработать процесс управления рисками проектов
- Внедрить практики Lean IT
- Разработать систему оценки эффективности проектов
Инновации и исследования
- Создать инновационную лабораторию или центр R&D
- Разработать процесс оценки и внедрения новых технологий
- Установить партнерские отношения с технологическими стартапами
- Внедрить программу внутренних инноваций и предложений сотрудников
- Разработать стратегию открытых инноваций
- Создать процесс пилотирования новых технологий
- Разработать стратегию использования блокчейн-технологий (если применимо)
- Исследовать возможности применения квантовых вычислений
- Оценить потенциал использования технологий виртуальной и дополненной реальности
- Разработать стратегию внедрения 5G и IoT
Управление персоналом и культура
- Провести оценку навыков IT-персонала
- Разработать план обучения и развития сотрудников
- Внедрить программу наставничества
- Разработать стратегию привлечения и удержания талантов
- Создать культуру непрерывного обучения и инноваций
- Внедрить программу признания и поощрения сотрудников
- Разработать план по повышению разнообразия и инклюзивности в IT-команде
- Внедрить практики well-being для IT-персонала
- Разработать стратегию управления удаленными командами
- Создать программу развития лидерских навыков для IT-менеджеров
-
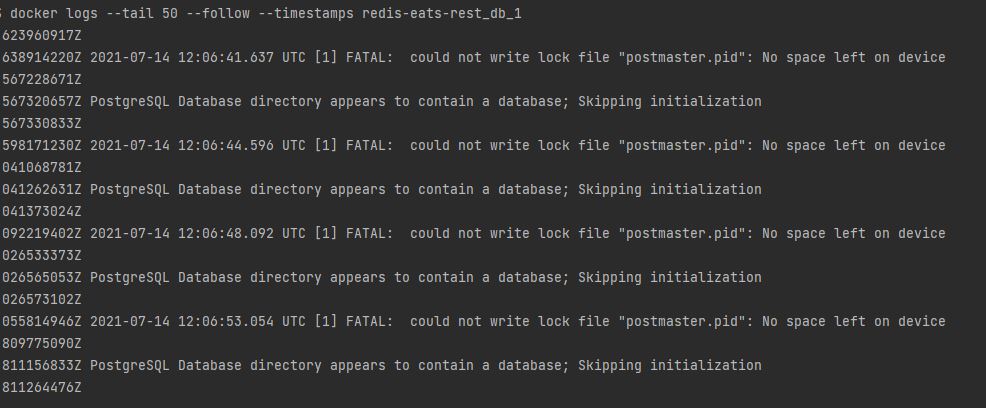
Docker контейнер перезагружается, как узнать почему?
К перезагружающемуся контейнеру невозможно подключиться, чтобы посмотреть, что выводится в консоль. Но в таких случаях нам поможет
docker logs:docker logs --tail 50 --follow --timestamps name_of_containerТут вы скорее всего и увидите, какая вылезает ошибка. В моем случае у меня просто кончилось свободное место на диске.
-

Как я искал и нашел IT-работу в 2021 году
Сегодня меня пригласил на вебинар по трудоустройству в качестве соведущего Алексей Голобурдин, автор канала Диджитализируй. Я согласился сразу — ведь во многом благодаря его каналу я ответил на многие вопросы на технических собеседованиях. С его разрешения публикую на своем блоге:
Для максимально стройного изложения своих мыслей я решил написать эту статью. У меня несколько необычный опыт в IT, но велика вероятность, что он поможет таким же специалистам, которые решили сменить сферу работы после 30.
Мой опыт в IT
Я пришел в технологии 12 лет назад предпринимателем. Я не делал проекты на заказ, я делал их для себя, сам ставил задачи, сам их выполнял. Так как я не был разработчиком в прямом смысле этого слова — решения я находил такие, которые можно установить на сервер своими силами через скрипты-установщики, связать через плагины или встраиваемые скрипты. Сейчас подобная парадигма называется No Code, так вот именно этим я и занимался всю свою карьеру. И, конечно, много опыта в бизнесе — ведь это были мои магазины, а значит маркетинг и продажи тоже должны быть настроены. До 2019 года я делал это все в команде с моими соучредителями, затем — уже самостоятельно, полный цикл решений.
Почему я решил идти в программирование?
В определенный момент времени ты понимаешь, что нужного тебе плагина не существует, или две системы не общаются между собой, но у каждой есть описание API. И чем дальше ты ищешь нужное тебе решение, тем больше убеждаешься, что его либо нет, либо оно сырое.
Так как я давно уже автоматизировал все в своем бизнесе — у меня было время на стороннее консультирование. Несколько лет я настраивал IT-системы в фитнес-клубе, делал их взаимосвязь, применял свой бизнес-опыт и профильное банковское образование для бизнес-консультирования. В общем, был занят. А в какой-то момент на мир спустился черный лебедь — пандемия. Естественно, фитнес-клуб закрыли одним из первых, и у меня появилось свободное время. И я решился — сейчас, пора. Python, я иду!
Обучение на курсе Яндекс.Практикума — Python-разработчик
У меня есть отдельная статья про Яндекс.Практикум, там есть плюсы и минусы. Рекомендую ознакомиться, здесь повторяться не буду. Здесь я сосредоточусь на тех шагах, которые я предпринял после обучения.
Подготовка к устройству на работу
Мне нужно было разобраться в моих знаниях. Я решил сделать это через книги. Понятное дело, что что-то могло пройти мимо. Я взялся за «Изучаем питон», «Чистый питон», «Грокаем алгоритмы», «Программист-прагматик» и другую литературу, которая гуглится по запросу «Лучшие книги по питону» и которые можно заказать на бумаге — с технической литературой я умею только так.
Также я начал участвовать в Open Source проектах. Нашел интересного ментора, Леона Сендоя, и помогал ему писать систему резервного копирования различных баз данных Blackbox. Читал код, разбирался в фабричном методе проектирования, и что самое главное — решал поставленные задачи. Причем почти все они были для меня абсолютно новыми, я разбирался в проблеме с нуля. Серьезный буст для саморазвития и в качестве бонуса ревью от очень хорошего норвежского специалиста и владельца сообщества Python-Discord на 200 000 человек.
Размещение резюме
Также я разместил резюме на HH и Хабр.Карьере. Я неплохо говорю по-английски, поэтому, проконсультировавшись с сестрой, которая уже много лет живет в Англии и работает HR, разместил резюме еще на следующих сайтах:
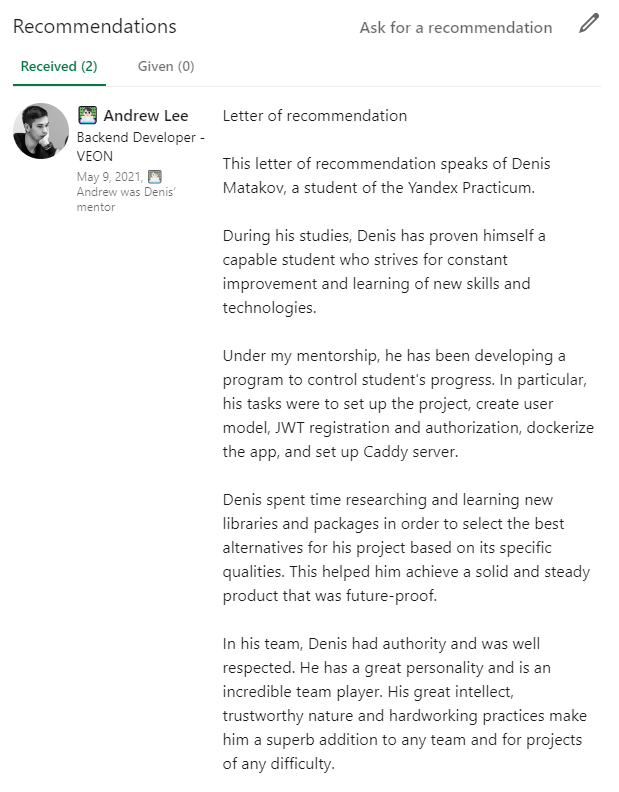
Также заручился рекомендациями от моих менторов — Леона Сендоя и Андрея Ли — на LinkedIn (рекомендации приложены в конце статьи для примера).
Первое собеседование
Довольно быстро пришло приглашение на первое собеседование на английском. Сказать что было страшно — ничего не сказать. Это был грандиозный выход из зоны комфорта. Но у меня есть один трюк, как бороться со страхом принятия решения — я его сразу принимаю. Не раздумывая, не переживая, да и еще раз да.
Теперь у меня был уже совсем другой повод беспокоиться — надо было готовиться к собеседованию на английском. Я составил речь, позвонил сестре, рассказал ей, она похвалила. Что ж, кажется я готов, подумал я.
Пройти собеседование с HR было несложно, но нервно. У меня красивая история, я подготовился — и вот у меня уже назначено техническое собеседование. Как мог я готовился, читал все, что попадалось под руки. Вот список того, что вам поможет в этом:
- https://www.pythoncheatsheet.org
- https://refactoring.guru/ru/design-patterns
- https://www.cyber-dojo.org/creator/home
- https://haseebq.com/my-ten-rules-for-negotiating-a-job-offer/
- https://kirill-sklyarenko.ru/lenta/150-voprosov-na-sobesedovanie-python-bez-opyta
- https://itvdn.com/ru/blog/article/interview-questions-python-developer
- https://github.com/yakimka/python_interview_questions
- https://www.youtube.com/watch?v=AWX4JnAnjBE&t=2284s
Техническое интервью тоже прошло на ура, я отвечал на вопросы, я знал как устроены некоторые сложные фичи питона и уверенно об этом говорил. Настало время технического задания, и вот тут я первый раз сделал все неправильно. Я прочитал задание, и сразу побежал выполнять. Я был слишком уверен в себе, ведь я понравился на всех этапах собеседования! И я решил задачу, получил данные по API, распечатал их в консоль, ничего сложного. Но техдиректору компании все это не понравилось от слова совсем. Потому что я не использовать паттерны проектирования, писал без классов, код нельзя было переиспользовать. Не то, что я не умел это делать — умел, но торопился, переживал, сделал тяп-ляп. Первый отказ. Я был чрезвычайно расстроен.
Следующие 30 собеседований
Дальше моя стратегия поменялась. Я должен был набрать опыт собеседований. Не важно, нравится ли мне компания или нет — я всегда откликался на все предложения разговоров от HR. Я внимательно изучал компанию, стек — по каждому непонятному слову сразу смотрел подробное руководство на Youtube (выбирал длинные ролики и скорость 1.75х). И с каждым разом отвечал все лучше. Попадались хитрые вопросы, попадались скучные, но почти всегда я проходил стадию HR на ура, а вот технические собеседования были успешны в 50% случаев.
Что стоит знать:
- напиши свой декоратор
- напиши свой декоратор с параметрами
- паттерны проектирования и где ты их применял
- SOLID, ACID, принципы ООП
- Нормализация БД и вообще вопросов на построение запроса к БД много, в основном на Postgres
- Базовые алгоритмы и их сложность
- Структуры данных
- Индексы и устройство хешей в общем виде
- Контекстный менеджер with
- REST/OpenAPI/принципы проектирования, SOAP
- Очереди Kafka и RabbitMQ
- AWS будет плюсом
- Redis
- Celery
- Асинхронное программирование и принцип работы GIL
- Микросервисы
- Рекурсия
- MongoDB
Два типа собеседований
Все можно поделить на два типа, вот и собеседования тоже. Первый тип — самый распространенный — собеседования, которые очень плохо подготовлены. Вопросы точечные, твой уровень никак не показывают, пытаются проверить не твои знания, а твой зубреж. Наверное, хороши для людей с идеальной памятью, я не из них. Я не могу вписать в поле название класса джанго, который я буду наследовать при создании своего фильтра — без подглядывания в документацию или проект, где я это уже делал.
Второй тип — это собеседования, где интервьюер выясняет область твоих знаний и четко начинает ходить по ее грани, пытаясь понять, как ты размышляешь, когда сталкиваешься с неизвестным. Вот из таких собеседований я выносил максимальное количество новой информации и именно они меня готовили к самому важному собеседованию — в компанию мечты.
Собеседование в EPAM
Так как компания ЕПАМ большая и ей уже 25 лет — то и процессы там гораздо лучше отлажены, в том числе собеседования. Это без преувеличения мой лучший опыт за весь период поиска работы. Ребята задавали интересные вопросы, где я что-то упускал — рассказывали, давали возможность раскрыться. Суммарно 5 часов технических собеседований, я был уставший, но довольный. Я рассказал свой опыт, я позиционировал себя как специалиста, который делает горизонтальный переход, и претендовал на должность Мидл-разработчика. Как я понял — позиционирование и вера в себя — это самые важные вещи после знаний.
И вот я получил оффер от ЕПАМ, и сразу на достойную сумму. Не принимая его сразу, я сказал, что мне нужно две недели на принятие решения и продолжил изучать рынок. Теперь была задана планка, и я хотел перепроверить — точно ли я правильно выбрал ЕПАМ.
Еще 10 собеседований, в том числе 3 технических, и я принял решение — я иду в ЕПАМ. Я пытался следовать советам из статей про то, как принимаются офферы и сколько надо выждать, но в итоге все равно договорился с HR о звонке и сообщил о своих намерениях. Всего процесс трудоустройства занял около трех месяцев, и это были самые насыщенные на учебу месяцы.
Пример резюме
Примеры моих резюме, если вам интересно как я себя позиционировал:
- https://tver.hh.ru/resume/5f9216eeff08885b8f0039ed1f784a526e3564
- www.linkedin.com/in/matakov
- https://career.habr.com/matakov-124318
Рекомендации от менторов
Обязательно собирайте рекомендации, они важны для принятия решения!

-
No code. Создаем программные продукты в визуальных редакторах.
В своих проектах я всегда придерживался философии «как можно меньше правок в фреймворк». Основная задача была сделать проект автообновляемым и не теряющим своей актуальности на протяжении долгого времени. Как я пришел к этой философии?
Почему No или Less Code?
Свои самые первые интернет-магазины я запускал в 2009-2010 годах, тогда не было еще того разнообразия готовых фреймворков и плагинов к ним. Был вордпресс, были скрипты интернет-магазинов с самоустановкой — укажи данные базы и проект начинает свое MVP-путешествие. Что происходило дальше? Если нужен новый заголовок, я лез в код и менял заголовок. Когда нужно было поставить какое-то условие в шаблоне — лез в Smarty и делал условие. Когда менялась логика бизнеса — я копал еще глубже и менял уже PHP-файлы. И вылилось это все в невозможность обновления продукта. А когда у вас успешный сайт, вам нужны новые функции для сохранения бизнеса в игре, и получить вы их можете только сделав еще больше правок в коде, или, как мы их называли всегда, костылей.
В итоге шли годы, а сайт устаревал, а сменить все и при этом сохранить трафик из поисковых систем — задача около нереальная. И когда все-таки этот момент наступал — наступали последствия в виде просадки позиций и падения продаж.
Концепция самообновляемости сайта
В итоге самым правильным решением для бизнеса стал переход на фреймворки с поддержкой плагинов. Таким образом, новые функции прилетали с обновлениями, плагины были изолированы от основного кода и всегда можно было заказать доработку под себя. Тут оставался простор для небольшого фронтенд кодинга, но все в очень жестких рамках.
No code сервисы
Не я один полюбил эту концепцию. В интернете появилось множество сервисов, которые стали помогать делать вам сайт совершенно без кода. Вы собираете интерфейс или даже целое мобильное приложение в визуальном редакторе. Если мои проекты все еще лежат на моих же серверах, то современные тенденции предлагают хранить их у провайдеров услуги за небольшие деньги и при этом всегда иметь возможность принять больше посетителей в моменте, чем позволил бы один свой сервер.
Рассмотрим некоторые из no code сервисов:
Скриншот из видео сверху (оригинал недоступен, сайт не работает):

webflow.com
Удивительный сервис, где даже базы данных нужно проектировать в визуальном интерфейсе. Получается, что это какой-то новый уровень разработки, и теперь можно делать не только сайты-визитки или посадочные страницы, но и полноценные системы управления контентом и онлайн-магазины!
editorx.com
Еще один сервис с возможностью полного проектирования как дизайна, так и базы данных. Проекты, построенные с помощью этой платформы — впечатляют.
bravostudio.app

Неожиданный поворот — это сервис Браво, позволяющий делать мобильные приложения без кода. В какой-то момент начинаешь понимать, что за этим всем будущее. Только сложные проекты с запутанной логикой будут писаться с нуля, все остальное можно будет сделать за пару вечеров без каких либо знаний программирования.
supernova.io
Сверхновую позиционируют уже не как no code, а как удобный код рядом с дизайном. Для тех, кто все еще хочет держать руку на пульсе, но уже хочет упростить себе жизнь.
Какие еще сервисы?
Обратите внимание на Notion (рич-блокнот с коллаборацией), Anima (ожившие прототипы), Play (дизайн мобильных приложений прямо на мобильных приложениях) и Airtable (прекрасная смесь экселя и баз данных).
-
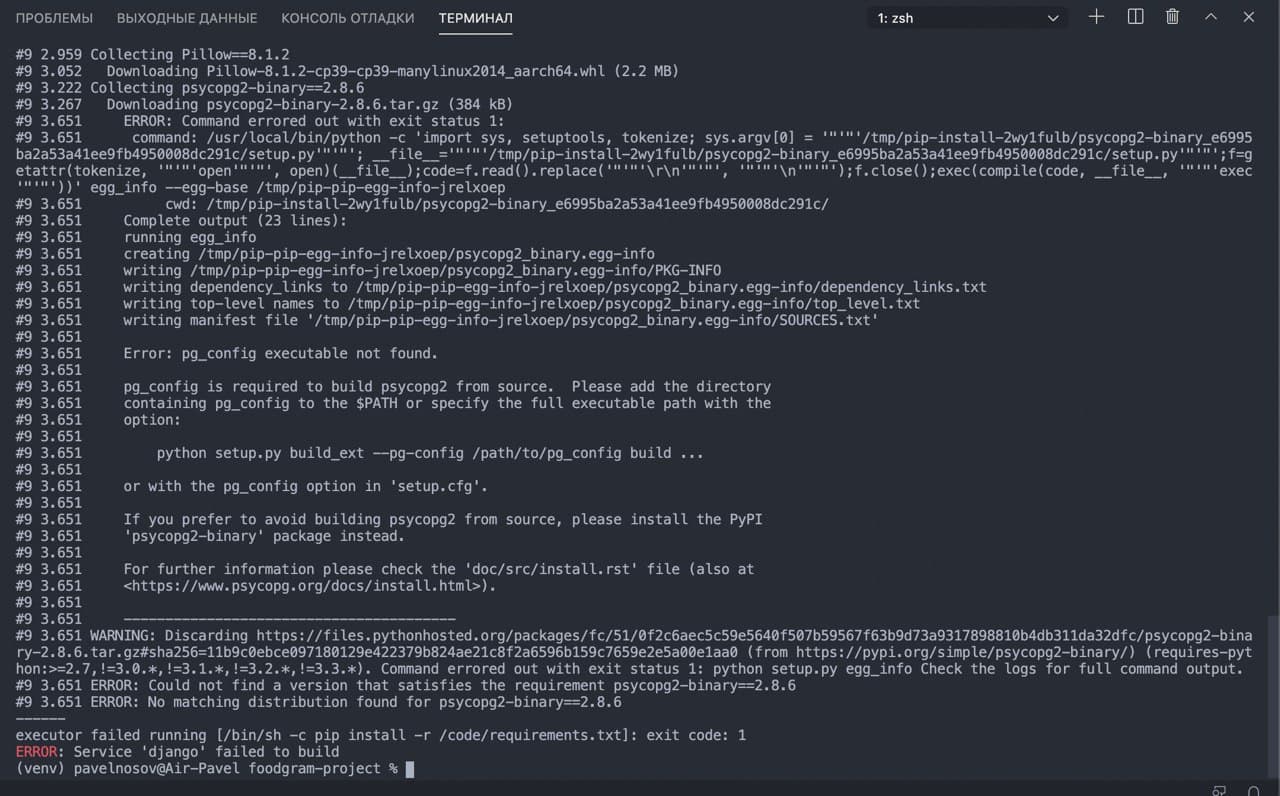
Как установить psycopg2-binary на Apple Silicon M1 Big Sur (в том числе в Docker)
Миграция на чип М1 от Apple прошла для меня практически бесшовно. Встретилась лишь одна проблема — с установкой
psycopg2-binary, что является утилитой, с помощью которой Django Framework подключается к PostgreSQL.Проблема неприятная и свежая, по ней много вопросов в англоязычной части интернета и очень мало хорошо расписанных инструкций. А на вариант с докером инструкции нет вовсе, это решение мне пришлось придумать самому.
Проблема 1: Не устанавливается psycopg2-binary в Docker-контейнере через Dockerfile или docker-compose (MacOS Big Sur M1)
Здесь самым простым способом будет отказаться от урезанных образов наподобие alpine или slim. Просто используйте самый обычный Python 3.9:FROM python:3.9После этого контейнеры поднимутся именно так, как вы их задумывали. Здесь, видимо, проблема в том, что архитектура чипа M1 пока неизвестна и не так популярна. В скором времени эту проблему наверняка исправят.
Проблема 2: Не устанавливается psycopg2-binary в MacOS Big Sur M1
Возможные выводы ошибки:
$ pip install psycopg2-binary Collecting psycopg2-binary Using cached psycopg2-binary-2.8.6.tar.gz (384 kB) ERROR: Command errored out with exit status 1:И дальше длинный трейс ошибки. Как победить? Если вы только купили свой мак, скорее всего у вас не установлен пакет
brewи вам нужно сделать следующие шаги:- Установите
brewhttps://brew.sh/ - Чтобы он запускался без указания полного пути вам нужно добавить этот путь (к многим другим путям) в переменную PATH. Не пугайтесь, это страшно лишь по началу. В unix-подобных системах терминал умеет запускать приложения только если он знает где их искать. А
brewустановилась в хитрую папку и наш терминал просто не знает этого пути. Пока не знает. Давайте его научим, и рекомендую запомнить этот трюк, он часто нужен (и не только на маках, но и на виндус). На вашем маке в качестве терминала по умолчанию стоит ZSH. Вам нужно создать файл в домашней директории (если там его еще нет, проверить можно командойls -la) с названием.zshrc(именно с точкой в начале) и положить туда одну строчку:
export PATH=/opt/homebrew/bin:$PATHПерезапустите терминал, теперь у вас есть
brew.3. Дальше проще, установите сам пакет с Постгресом
brew install postgresql4. Теперь установите SSL, без него не заработает
brew link openssl5. Пропишите в наш созданный в пункте 2 файл еще один путь:
echo 'export PATH="/opt/homebrew/opt/openssl@1.1/bin:$PATH"' >> ~/.zshrc6. И финальный аккорд! Устанавливаем
psycopg2-binaryс необходимыми переменными окружения (внимание, это все одна команда, просто очень длинная):LDFLAGS="-L/opt/homebrew/opt/openssl@1.1/lib" CPPFLAGS="-I/opt/homebrew/opt/openssl@1.1/include" PKG_CONFIG_PATH="/opt/homebrew/opt/openssl@1.1/lib/pkgconfig" pip install psycopg2-binaryЕсли на каком-то этапе что-то пошло не так, попробуйте изучить эту тему.
- Установите
-

Список технологий для изучения
Получил список рекомендаций от знакомого разработчика — что нужно знать, программа-минимум. Решил оставить в блоге этот перечень, чтобы не затерялся. Итак:
- Как минимум поверхностное понимание работы JavaScript
- Если учить React, то сфокусироваться на практическом применении, а также разобраться с фреймворками на его основе, например next.js, который позволяет обойтись без бэкенда вовсе
- Ознакомиться с технологиями публикации сайтов прямо из репозитория, например Netfly
- Понять JAMstack, так как он очень популярен и удобен
- Взять на вооружение технологию htmx, которая позволяет сделать отзывчивый интерактивный сайт без JS, только на питоне
- Узнать больше про безсерверную архитектуру на основе AWS и Lambdas (причем докер образы будут прямо в Лямбде). В питоне это позволяет сделать утилита Zappa
Также общий набор рекомендаций для софт-скиллов:
- Писать хорошие коммиты
- Уметь делать CI/CD
- Писать тесты для своих проектов на гитхабе
- Проявлять активность на гитхабе в целом
- Писать красивый PEP8 код
- Писать статьи в блог
- Может, даже вести подкаст
- Помогать с опен-сорс проектами
И это ведь только начало. Впереди столько интересных технологий!
-
Bulma для всех, кто боится Bootstrap
Как начинающий разработчик, я, безусловно, пользовался бутстрапом. Это такой красивый CSS-фреймворк, который помогает сайтам от разработчиков выглядеть симпатично даже без фронтендера в команде. Но любая попытка сделать красивую кнопку заводила меня в документацию, так как набор переменных в стилях там запомнить совершенно невозможно.
И вот тут на помощь пришла Bulma. Это по сути своей тот же Bootstrap, только с человеческими названиями классов. Хотите кнопку? Класс называется
button. Хотите колонки? Пишитеcolumns, а внутри для каждой колонкиcolumn. Считаю, что Бульму надо включить обязательное изучение во всех курсах бэкендеров.Обязательно посмотрите их вводное видео:
-

Закончил курс Яндекс.Практикума Python-разработчик
Завершилась большая и интересная глава в моей жизни. В начале прошлого лета в разгар эпидемии и в расцвет онлайн-обучения я решил, что стоит воспользоваться возможностью и получить, наконец, образование в области программирования и разработки. Все это время я оставался самоучкой, знал много разных языков и синтаксисов, но из-за отсутствия базового понимания взаимодействия элементов инфраструктуры разработки я не мог сдвинуться с мертвой точки. Мне все легко давалось до определенного предела, а дальше — сразу лес густой, иначе не скажешь. Но эти 9 месяцев все изменили.

Базовый синтаксис Питона я знал еще до Яндекс.Практикума, заканчивал курсы от Гугла. Поэтому первая часть далась мне относительно легко и я наивно полагал, что так и продолжится. Но нет.
Возможности бэкенда, вторая часть курса, показали мне, что из Питона можно сделать огромный веб-фреймворк, которым еще нужно научиться управлять. Получается, что это язык внутри языка. Да, логический синтаксис тот же самый, но все остальные команды — совсем другой разговор. Под конец этой главы нам еще и дали в финальном задании новую концепцию — представления, основанные на классах. Понять ее было очень не просто, но она действительно сильна и помогает ускорить разработку.
Третья часть была по API. На мой взгляд, эта тема наравне с вводной частью по сложности. А вот интересности ей не занимать. Подключаться к внешним сервисам, получать информацию, обрабатывать ее, делать ботов — мечта, а не профессия.
Дальше, к сожалению, не все так весело было. Алгоритмы и структуры данных в курсе были поданы очень вяло, а теория была совершенно не применима в практике. Объясняют рекурсию, дают задачу, ты решаешь ее рекурсией и не можешь уложиться в заданные параметры по памяти и времени. В итоге большинство задач решались лишь определенными алгоритмами и похоже это было скорее на олимпиаду, чем на обучение. После сдачи этой части я прочел самостоятельно книгу «Грокаем алгоритмы» и понял гораздо больше, чем дал Практикум. Говорят, эти главы переписывают и даже уже переписали, но факт остается фактом — часть слабая.
Пятая глава обучения началась очень хорошо, заинтересовала серверами и докером, но в какой-то момент у авторов кончились силы и дальше пошло лишь «вставьте это в командную строку» и «смотрите, все получилось». Почему получилось? Что за параметры у команды были? Здесь у меня произошел переломный момент. Я начал докапываться до сути. Я составил список вопросов, пришел на вебинар и целый час выяснял у наставника как это все работает. Получил ответы, пошел их применять и опять начались несостыковки. Но тема докера меня всегда привлекала, и я решил разобраться. Так на этом сайте родилась серия статей про деплой, я прочитал всю документацию, придумал несколько способов сделать деплой, с каждой статьей улучшал свои познания и в какой-то момент постиг дзен. Докер стал для меня настолько родным, что я начал с удовольствием помогать однокурсникам и объяснять им, почему и как именно у них не работали проекты. Сложная глава, но по ней у меня самые лучшие знания остались.
Шестая глава — дипломный проект. По началу все казалось достаточно простым, но потом выяснилось, что предоставленный нам фронтент был написан без DRY подхода — там постоянно и везде повторялся один и тот же код не только в HTML, но и в JavaScript и CSS. Это невероятно усложнило понимание и так не самой ясной для нас технологии. А на этапе оживления формы я вообще был готов сдаться — нас не просто учили другому, нам даже банально не объяснили как объект формы выглядит изнутри. Какое-то невероятное усилие и обратный инжиниринг все-таки помогли мне справиться с формой, дальше уже было легче. Но я твердо понял, что на факультет фронтента Практикума я не пойду, если там допустили такое.
Сейчас я сдал дипломный проект и жду выпускного. Безусловно, я безумно рад, что не сдался, что 9 месяцев был на одной волне со своим курсом в сто с лишним человек. Яндекс.Практикум помог с пониманием маршрута по знаниям и в половине случаев эти знания дал. В другой половине — помогла документация и одногруппники.
Формат вебинаров мне показался абсолютно бестолковым. Любую тему можно в два-четыре раза быстрее познать на Youtube, чем от наставников, да и буду честен — речь у них плохо поставлена, много слов-паразитов и в основном не очень адекватная подготовка к занятию. Вторую половину курса я вебинары не смотрел.
Чего не хватает — так это списка литературы, а точнее ссылок на нужную документацию к заданиям, на видеоуроки, на статьи на тему, да даже на Stackoverflow. Понятно, что нужно учиться самому искать, но при объяснении темы нужно дать максимально адекватный перечень дополнительных материалов.
Я долго думал, чем я займусь дальше. Многие уже ищут работу, но я решил познать как можно больше про технологии фронтенда, про JavaScript и фреймворки, основанные на нем. А также знакомый разработчик дал мне список технологий, которые нужно знать и понимать в современном мире. О них я расскажу в будущих статьях на этом сайте, подписывайтесь на обновления.
-
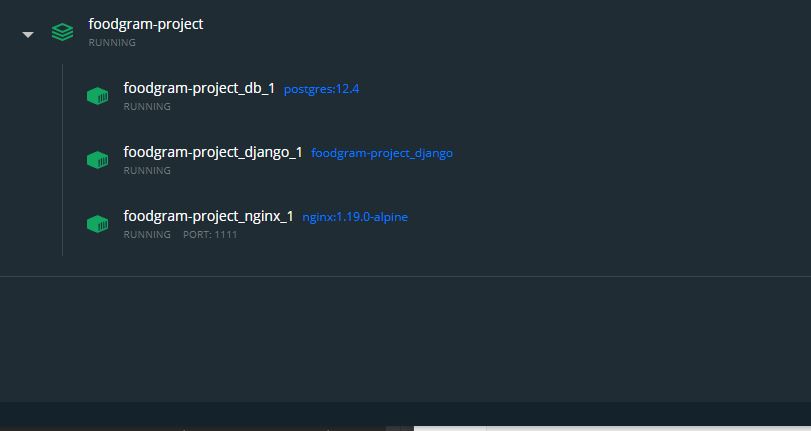
Docker-compose для разработки: видим изменения на лету
Docker-compose — невероятно мощный инструмент не только для деплоя в продакшине, но и для разработки. Для максимального удобства концептуально нам нужно применить в нем всего один прием — заменить тома на папки. Таким образом, наш проект будет иметь прямой доступ к хостовой машине и любые правки, которые мы будем вносить, будут в реальном времени отображаться в контейнерах.
Давайте рассмотрим код-пример:
version: '3.8' volumes: postgres_data: services: db: image: postgres:12.4 restart: always volumes: - postgres_data:/var/lib/postgresql/data/ env_file: - ./.env django: build: . depends_on: - db restart: always env_file: - ./.env volumes: - .:/code/ entrypoint: /code/entrypoint.sh nginx: image: nginx:1.19.0-alpine ports: - "127.0.0.1:1111:80" volumes: - ./static:/code/static - ./media:/code/media - ./nginx:/etc/nginx/conf.d/ depends_on: - django restart: alwaysМы оставили на томе только базу данных. Все остальные данные вместо этого мы прикрепили к нужным папкам в нашем проекте.
Смотрите, весь корень проекта в папке code, статика и медиа подключена напрямую к контейнеру nginx, как и его конфиг. Вот как он выглядит:
upstream djangodocker { server django:8000; } server { listen 80; location / { proxy_pass http://djangodocker; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $host; proxy_redirect off; } location /static/ { alias /code/static/; } location /media/ { alias /code/static/; } }Описание того, что здесь происходит, можно найти в статье про docker-compose. Там же вы увидите разбор entrypoint.sh:
#!/bin/sh sleep 2 python manage.py migrate python manage.py createcachetable if [ "$DJANGO_SUPERUSER_USERNAME" ]; then python manage.py createsuperuser \ --noinput \ --username "$DJANGO_SUPERUSER_USERNAME" \ --email $DJANGO_SUPERUSER_EMAIL fi python manage.py collectstatic --noinput gunicorn foodgram.wsgi:application --bind 0.0.0.0:8000 exec "$@"Тут добавлено автоматическое создание суперюзера, удобный в разработке момент. Для этого нужно добавить пару переменных в .env:
DB_ENGINE=django.db.backends.postgresql # указываем, что работаем с postgresql DB_NAME=postgres # имя базы данных POSTGRES_USER=postgres # логин для подключения к базе данных POSTGRES_PASSWORD=postgrespostgres # пароль для подключения к БД (установите свой) DB_HOST=db # название сервиса (контейнера) DB_PORT=5432 # порт для подключения к БД SECRET_KEY=SECRET_KEYSECRET_KEYSECRET_KEY DJANGO_SUPERUSER_PASSWORD=12345678 DJANGO_SUPERUSER_EMAIL=example@example.com DJANGO_SUPERUSER_USERNAME=adminЧтобы новая установка Django подключилась к Postgres — измените настройки подключения в файле settings.py:
DATABASES = { 'default': { 'ENGINE': os.environ.get('DB_ENGINE'), 'NAME': os.environ.get('DB_NAME'), 'USER': os.environ.get('POSTGRES_USER'), 'PASSWORD': os.environ.get('POSTGRES_PASSWORD'), 'HOST': os.environ.get('DB_HOST'), 'PORT': os.environ.get('DB_PORT'), } }И не забудьте, что для работы базы данных вам нужна зависимость:
pip install psycopg2-binaryЕще один важный момент — это изменения в файле Dockerfile. Теперь нам не нужно копировать весь проект на контейнер, мы и так туда подключим всю папку, но предварительная установка зависимостей и старт контейнера зависят от двух файлов, которые уже должны быть в контейнере:
FROM python:3.9-slim ENV PYTHONDONTWRITEBYTECODE 1 ENV PYTHONUNBUFFERED 1 WORKDIR /code #COPY . /code COPY ./requirements.txt /code COPY ./entrypoint.sh /code RUN pip install -r /code/requirements.txt ENTRYPOINT ["/code/entrypoint.sh"]После этого вы просто запускаете команду docker-compose up и получаете рабочий прототип проекта на своей машине, со статикой:
И что самое важное, вы сможете вносить изменения на лету и тут же их видеть!
Отдельное спасибо за идею с прямым подключением файлов Leon Sandøy в его репозитории Django-Starter. Добавил сюда nginx и автоматическое применение миграций.