-
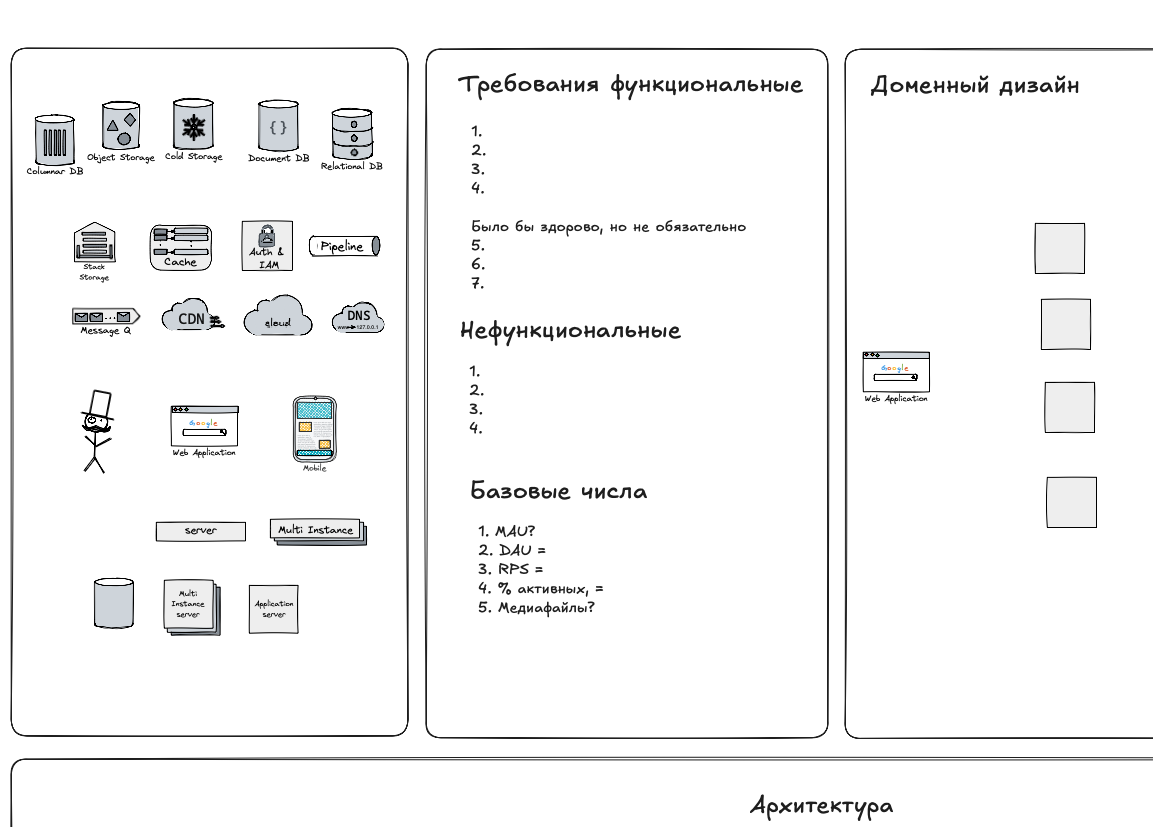
Шаблон Excalidraw для проведения интервью по системному дизайну
Для проведения интервью можно использовать следующий шаблон — позволяет структурировать ответ и не забыть спросить основные моменты, необходимые для проектирования:
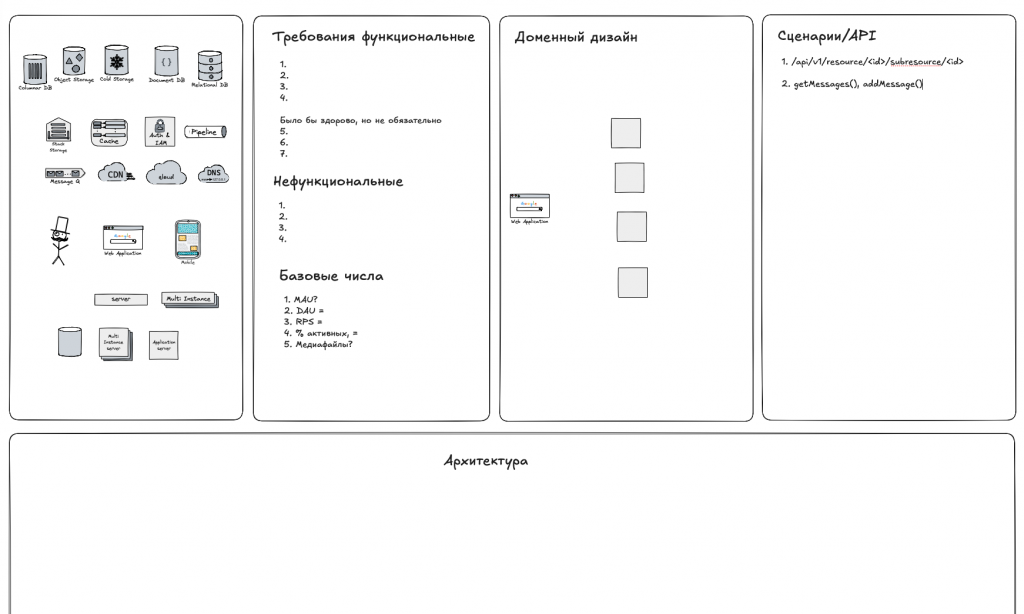
Скачать шаблон для https://excalidraw.com/
-

Сколько вебсокетов можно открыть на один чат сервер?
Количество WebSocket-соединений, которые можно открыть на одном чат-сервере, зависит от нескольких факторов, но теоретически это число может быть очень большим. Рассмотрим основные аспекты:
Теоретический максимум
Теоретически, максимальное количество WebSocket-соединений на одном сервере может достигать огромных значений. Каждое соединение уникально идентифицируется комбинацией IP-адреса клиента и порта источника. Это означает, что теоретический предел составляет около 2^48 (примерно 281 триллион) соединений на один порт сервера.
Практические ограничения
На практике количество соединений ограничивается несколькими факторами:
- Ресурсы сервера: Память, CPU и пропускная способность сети являются ключевыми ограничивающими факторами.
- Настройки операционной системы: Лимиты на количество открытых файловых дескрипторов и сетевых соединений могут ограничивать максимальное число WebSocket-соединений.
- Производительность сервера: С увеличением числа соединений может падать общая производительность системы.
Реальные примеры
- WhatsApp и Phoenix: Эти платформы достигли показателя в 2 миллиона одновременных WebSocket-подключений на одном сервере.
- Эксперименты с Java: Исследователи смогли открыть более миллиона TCP-соединений на одном сервере, что применимо и к WebSocket.
Оптимизация для большого количества соединений
Для поддержки большого числа WebSocket-соединений рекомендуется:
- Использовать асинхронные библиотеки: Они значительно повышают производительность за счет одновременной обработки задач.
- Поддерживать многопоточность: Автоматическая или ручная настройка многопоточности помогает масштабировать производительность.
- Выбирать эффективные языки и фреймворки: NodeJS, Java и C# показали хорошие результаты в тестах производительности WebSocket-серверов.
- Оптимизировать настройки сервера: Увеличение лимитов на файловые дескрипторы и сетевые соединения в ОС может существенно повысить возможности сервера.
- Использовать балансировку нагрузки: Распределение соединений между несколькими серверами позволяет масштабировать систему горизонтально.
В заключение, хотя теоретически возможно открыть миллионы WebSocket-соединений на одном сервере, практическое количество будет зависеть от конкретной конфигурации оборудования, оптимизации программного обеспечения и требований к производительности вашего чат-приложения. Для большинства реальных сценариев использования чат-сервер может эффективно обслуживать тысячи или даже десятки тысяч одновременных WebSocket-соединений при правильной настройке и оптимизации.
-

Какой фреймворк выбрать на основе RPS (Request per second)
Фреймворк Язык RPS Удобство Экосистема Сообщество Документация Масштабируемость Безопасность Интеграция Actix Rust 100000 7 7 8 8 9 9 7 Warp Rust 90000 7 6 7 7 9 9 7 ASP.NET Core C# 60000 9 9 9 9 9 9 9 Fiber Go 60000 8 7 8 8 8 8 8 Gin Go 55000 8 8 9 8 8 8 8 Fastify JS 60000 9 8 8 9 8 8 9 NestJS JS 50000 9 9 9 9 9 9 9 Spring Boot Java 40000 8 10 10 9 10 9 10 Micronaut Java 35000 8 8 7 8 9 9 8 FastAPI Python 30000 9 8 8 9 8 8 8 Django Python 2000 9 10 10 10 8 9 9 Hanami Ruby 2000 7 7 7 7 7 8 7 Rails Ruby 1900 10 10 10 9 8 8 9 Laravel PHP 1000 9 9 10 10 8 8 9 Symfony PHP 900 8 9 9 9 9 9 9 - Удобство: Насколько легко начать работу и разрабатывать с использованием фреймворка.
- Экосистема: Разнообразие и качество доступных библиотек и инструментов.
- Сообщество: Активность и размер сообщества разработчиков.
- Документация: Качество и полнота официальной документации.
- Масштабируемость: Способность фреймворка справляться с ростом нагрузки и размера приложения.
- Безопасность: Встроенные механизмы безопасности и легкость их реализации.
- Интеграция: Простота интеграции с другими технологиями и сервисами.
При выборе фреймворка следует учитывать все эти факторы в контексте конкретного проекта. Например:
- Для быстрой разработки прототипов могут подойти Ruby on Rails или Django.
- Для высоконагруженных систем стоит обратить внимание на Actix, ASP.NET Core или Spring Boot.
- Если важна гибкость и легковесность, то Fastify или Gin могут быть хорошим выбором.
- Для корпоративных приложений с сложной бизнес-логикой Spring Boot или ASP.NET Core предоставляют широкие возможности.
Сколько серверов надо?
MAU (10^n) DAU RPS Серверы (Fiber) Серверы (Django) 10000 (10^4) 3 500 0.61 1 1 100000 (10^5) 35 000 6.08 1 1 1000000 (10^6) 350 000 60.76 1 1 10000000 (10^7) 3 500 000 607.64 1 1 100000000 (10^8) 35 000 000 6076.39 1 4 1000000000 (10^9) 350 000 000 60763.89 2 31 -

Согласованное и рандеву хеширование
Согласованное хеширование (Consistent hashing) — это специальная техника хеширования в компьютерных науках, которая обладает важным свойством: при изменении размера хеш-таблицы требуется перераспределить в среднем только n/m ключей, где n — количество ключей, а m — количество слотов.
Основные особенности
- Эффективность при масштабировании: В отличие от традиционных хеш-таблиц, где изменение количества слотов приводит к перераспределению почти всех ключей, согласованное хеширование минимизирует количество перемещаемых данных.
- Распределение нагрузки: Техника равномерно распределяет ключи кэша по шардам, даже если некоторые шарды выходят из строя или становятся недоступными.
Применение
Согласованное хеширование широко используется в распределенных системах, особенно в:
- Распределенных кэшах
- Системах хранения данных (например, Amazon Dynamo)
- Сетях доставки контента (CDN)
- Балансировке нагрузки
Принцип работы
- Ключи и серверы отображаются на виртуальную окружность (обычно от 0 до 2π).
- Каждый ключ назначается ближайшему серверу по часовой стрелке.
- При добавлении или удалении сервера перераспределяются только ключи, попадающие в его сегмент.
Преимущества
- Минимизация перераспределения данных при изменении количества серверов.
- Улучшение масштабируемости и отказоустойчивости распределенных систем.
Согласованное хеширование стало ключевой технологией для многих современных распределенных систем, обеспечивая эффективное распределение данных и нагрузки
Рандеву-хеширование (Rendezvous hashing) или хеширование с наибольшим случайным весом (HRW) — это алгоритм, позволяющий клиентам достичь распределенного соглашения о выборе k вариантов из n возможных. Этот метод часто применяется в распределенных системах для назначения объектов серверам или прокси.
Основные особенности
- Простота: Алгоритм концептуально прост и легок в реализации.
- Минимальное нарушение: При добавлении или удалении узла перераспределяются только объекты, связанные с этим узлом.
- Равномерное распределение: Обеспечивает равномерное распределение объектов по узлам.
- Поддержка взвешивания: Позволяет учитывать разную мощность узлов.
Принцип работы
- Для каждого объекта и каждого узла вычисляется хеш-значение.
- Объект назначается узлу с наибольшим хеш-значением.
- При изменении набора узлов пересчитываются только затронутые объекты.
Применение
Рандеву-хеширование используется во многих реальных системах, включая:
- Балансировщик нагрузки GitHub
- Распределенная база данных Apache Ignite
- Файловое хранилище Tahoe-LAFS
- Pub/sub платформа Twitter EventBus
Преимущества перед согласованным хешированием
- Более простая концепция и реализация
- Не требует предварительных вычислений или хранения токенов
- Обеспечивает простое решение для распределенного k-соглашения
Рандеву-хеширование становится все более популярным в современных распределенных системах благодаря своей простоте, эффективности и гибкости
Характеристика Согласованное хеширование Рандеву-хеширование Год изобретения 1997 1996 Сложность Более сложный Проще Метод отображения Отображает узлы и ключи на кольцо хеширования Вычисляет хеш-значения для каждой пары ключ-узел Размещение объектов По часовой стрелке на хеш-кольце Выбирает узел с наибольшим хеш-значением Балансировка нагрузки Хорошая, но могут быть горячие точки В целом лучше, более равномерная Масштабируемость Хорошо масштабируется при инкрементных изменениях Менее масштабируемо, пересчитывает все хеши Предварительные вычисления токенов Требует предварительного вычисления и хранения токенов Не требует предварительных вычислений токенов Сложность добавления/удаления узлов O(K/N + log N) O(n) для базовой реализации Перераспределение ключей Минимальное перемещение ключей Объекты перераспределяются на оставшиеся узлы Реальное использование Cassandra, Couchbase GitHub Load Balancer, Apache Ignite, Twitter EventBus -

Какую базу использовать для высоконагруженного приложения?
База данных CAP QPS Масштабирование Оптимизация In memory/Disk based Область применения Apache Cassandra AP До 1 000 000 Горизонтальное Write Disk based Большие данные, IoT Memcached CP До 1 000 000 Горизонтальное Read In memory Кэширование, веб-приложения Redis CP До 500 000+ Горизонтальное Read/Write In memory Кэширование, сессии Amazon DynamoDB AP До 500 000 Автоматическое горизонтальное Read/Write Disk based Веб-приложения, мобильные приложения ClickHouse CP До 300 000 Горизонтальное Read/Write Disk based Аналитика, большие данные Couchbase AP До 200 000 Горизонтальное Read/Write Hybrid Веб-приложения, мобильные приложения PostgreSQL CA До 150 000 Вертикальное, репликация Read Disk based Транзакционные системы, ГИС Oracle Database CA До 120 000 Вертикальное, RAC кластеры Read/Write Disk based Корпоративные приложения, финансы MongoDB CP До 100 000 Горизонтальное и вертикальное Read/Write Disk based Веб-приложения, IoT MySQL CA До 100 000 Вертикальное, репликация Read Disk based Веб-сайты, CMS Etcd CP До 80 000 Горизонтальное Read Disk based Распределенные системы, конфигурации Apache HBase CP До 30 000 Горизонтальное Write Disk based Большие данные, аналитика Microsoft Azure Cosmos DB AP Варьируется Горизонтальное Read/Write Disk based Глобально распределенные приложения InfluxDB CP Варьируется Горизонтальное Read/Write Disk based IoT, мониторинг PostGIS CA Варьируется Вертикальное, репликация Read Disk based ГИС, картография Apache Spark SQL CP Варьируется Горизонтальное Read/Write In memory Аналитика больших данных OpenSearch AP Варьируется Горизонтальное Read Disk based Поиск, логи CouchDB AP Варьируется Горизонтальное Read/Write Disk based Веб-приложения, мобильные приложения Firebird CA Варьируется Вертикальное, репликация Read/Write Disk based Встраиваемые системы, локальные приложения Примечания:
- «In memory» означает, что база данных хранит данные преимущественно в оперативной памяти для быстрого доступа.
- «Disk based» означает, что база данных в основном хранит данные на диске.
- «Hybrid» (как в случае с Couchbase) означает, что база данных использует как память, так и диск для оптимальной производительности.
- Значения QPS являются приблизительными и могут варьироваться в зависимости от конфигурации и нагрузки.
-

Памятка по системному дизайну
Выбор правильной архитектуры = Выбор правильных сражений + Управление компромиссами
Перевод: https://gist.github.com/vasanthk/485d1c25737e8e72759f
Основные шаги
- Уточнить и согласовать масштаб системы
- Варианты использования (описание последовательностей событий, которые в совокупности приводят к полезному действию системы)
- Кто будет использовать систему?
- Как они будут ее использовать?
- Ограничения
- В основном определите ограничения по обработке трафика и данных в масштабе.
- Масштаб системы (запросы в секунду, типы запросов, объем записываемых данных в секунду, объем считываемых данных в секунду)
- Особые системные требования, такие как многопоточность, ориентация на чтение или запись.
- Проектирование архитектуры высокого уровня (абстрактный дизайн)
- Набросайте важные компоненты и связи между ними, не вдаваясь в детали.
- Уровень сервиса приложений (обслуживает запросы)
- Перечислите различные необходимые сервисы.
- Уровень хранения данных
- Например, масштабируемая система обычно включает веб-сервер (балансировщик нагрузки, load balancer), сервис (разделение сервисов, service partition), базу данных (кластер баз данных master/slave) и системы кэширования.
- Проектирование компонентов
- Компоненты + конкретные API, необходимые для каждого из них.
- Объектно-ориентированный дизайн для функциональности.
- Сопоставление функций с модулями: один сценарий для одного модуля.
- Рассмотрите отношения между модулями:
- Некоторые функции должны иметь уникальный экземпляр (Одиночки, Singletons)
- Основной объект может состоять из многих других объектов (композиция, composition)
- Один объект является другим объектом (наследование, inheritance)
- Проектирование схемы базы данных.
- Понимание узких мест
- Возможно, вашей системе нужен балансировщик нагрузки и множество машин за ним для обработки пользовательских запросов.
- Или, возможно, данных так много, что вам нужно распределить базу данных на несколько машин. Каковы некоторые недостатки, возникающие при этом?
- Слишком ли медленная база данных и нуждается ли она в кэшировании в памяти?
- Масштабирование абстрактного дизайна
- Вертикальное масштабирование (vertical scaling)
- Масштабирование путем добавления большей мощности (CPU, RAM) к существующей машине.
- Горизонтальное масштабирование (horizontal scaling)
- Масштабирование путем добавления большего количества машин в пул ресурсов.
Кэширование (Caching)
Балансировка нагрузки помогает масштабироваться горизонтально на постоянно растущем числе серверов, но кэширование позволит вам гораздо эффективнее использовать уже имеющиеся ресурсы, а также сделает возможными иначе недостижимые требования к продукту.
- Кэширование приложений требует явной интеграции в код приложения. Обычно оно проверяет, есть ли значение в кэше; если нет, извлекает значение из базы данных.
- Кэширование базы данных, как правило, «бесплатно». Когда вы включаете базу данных, вы получаете некоторый уровень настройки по умолчанию, который обеспечит определенную степень кэширования и производительности.
- Кэши в памяти (in-memory caches) наиболее мощны с точки зрения чистой производительности. Это потому, что они хранят весь набор данных в памяти, а доступ к RAM на порядки быстрее, чем к диску. Например, Memcached или Redis.
Примеры:
- Предварительный расчет результатов (например, количество посещений с каждого реферального домена за предыдущий день)
- Предварительное создание дорогостоящих индексов (например, предлагаемые истории на основе истории кликов пользователя)
- Хранение копий часто запрашиваемых данных в более быстром бэкенде (например, Memcache вместо PostgreSQL)
Балансировка нагрузки (Load balancing)
Публичные серверы масштабируемого веб-сервиса скрыты за балансировщиком нагрузки. Этот балансировщик нагрузки равномерно распределяет нагрузку (запросы от ваших пользователей) на вашу группу/кластер серверов приложений.
Типы:
- Умный клиент (трудно сделать идеально)
- Аппаратные балансировщики нагрузки (дорого, но надежно)
- Программные балансировщики нагрузки (гибридные — подходят для большинства систем)
Репликация базы данных (Database replication)
Репликация базы данных — это частое электронное копирование данных из базы данных на одном компьютере или сервере в базу данных на другом, чтобы все пользователи имели доступ к одному уровню информации. Результатом является распределенная база данных, в которой пользователи могут получить доступ к данным, относящимся к их задачам, не мешая работе других. Реализация репликации базы данных с целью устранения неоднозначности или несогласованности данных между пользователями известна как нормализация.
Партиционирование базы данных (Database partitioning)
Партиционирование реляционных данных обычно относится к разложению ваших таблиц либо по строкам (горизонтально), либо по столбцам (вертикально).
Map-Reduce
Для достаточно небольших систем вы часто можете обойтись специальными запросами к SQL-базе данных, но этот подход может не масштабироваться тривиально, когда количество хранимых данных или нагрузка на запись требует шардинга вашей базы данных, и обычно требует выделенных подчиненных узлов для выполнения этих запросов (в этот момент, возможно, вы предпочтете использовать систему, разработанную для анализа больших объемов данных, вместо борьбы с вашей базой данных).
Добавление слоя map-reduce позволяет выполнять интенсивные операции с данными и/или обработкой за разумное время. Вы можете использовать его для расчета предлагаемых пользователей в социальном графе или для создания аналитических отчетов. Например, Hadoop, и, возможно, Hive или HBase.
Платформенный слой (Сервисы) (Platform Layer (Services))
Разделение платформы и веб-приложения позволяет масштабировать части независимо. Если вы добавляете новый API, вы можете добавить серверы платформы без добавления ненужной мощности для уровня веб-приложения.
Добавление платформенного слоя может быть способом повторного использования вашей инфраструктуры для нескольких продуктов или интерфейсов (веб-приложение, API, приложение для iPhone и т.д.) без написания слишком большого количества избыточного шаблонного кода для работы с кэшами, базами данных и т.д.
Ключевые темы для проектирования системы
- Параллелизм (Concurrency)
- Понимаете ли вы потоки, взаимоблокировку и голодание? Знаете ли вы, как распараллеливать алгоритмы? Понимаете ли вы согласованность и когерентность?
- Сетевое взаимодействие (Networking)
- Примерно понимаете ли вы IPC и TCP/IP? Знаете ли вы разницу между пропускной способностью и задержкой, и когда каждый фактор является релевантным?
- Абстракция (Abstraction)
- Вы должны понимать системы, на которых вы строите. Знаете ли вы примерно, как работают ОС, файловая система и база данных? Знаете ли вы о различных уровнях кэширования в современной ОС?
- Производительность в реальном мире (Real-World Performance)
- Вы должны быть знакомы со скоростью всего, что может делать ваш компьютер, включая относительную производительность RAM, диска, SSD и вашей сети.
- Оценка (Estimation)
- Оценка, особенно в форме приблизительного расчета, важна, потому что она помогает вам сузить список возможных решений только до тех, которые осуществимы. Тогда вам нужно написать только несколько прототипов или микро-бенчмарков.
- Доступность и надежность (Availability & Reliability)
- Думаете ли вы о том, как вещи могут выйти из строя, особенно в распределенной среде? Знаете ли вы, как проектировать систему для борьбы с сетевыми сбоями? Понимаете ли вы долговечность?
Соображения по проектированию системы веб-приложений:
- Безопасность (CORS)
- Использование CDN
- Сеть доставки контента (CDN) — это система распределенных серверов (сеть), которая доставляет веб-страницы и другой веб-контент пользователю на основе географического расположения пользователя, происхождения веб-страницы и сервера доставки контента.
- Эта услуга эффективна для ускорения доставки контента веб-сайтов с высоким трафиком и веб-сайтов с глобальным охватом. Чем ближе сервер CDN географически к пользователю, тем быстрее контент будет доставлен пользователю.
- CDN также обеспечивают защиту от больших всплесков трафика.
- Полнотекстовый поиск (Full Text Search)
- Использование Sphinx/Lucene/Solr — которые достигают быстрых поисковых ответов, потому что вместо прямого поиска по тексту они ищут по индексу.
- Автономная поддержка/Прогрессивное улучшение
- Service Workers
- Web Workers
- Серверный рендеринг (Server Side rendering)
- Асинхронная загрузка активов (Lazy load items)
- Минимизация сетевых запросов (Http2 + bundling/sprites и т.д.)
- Продуктивность разработчиков/Инструментарий
- Доступность (Accessibility)
- Интернационализация
- Отзывчивый дизайн (Responsive design)
- Совместимость браузеров
Рабочие компоненты архитектуры фронтенда
- Код
- HTML5/WAI-ARIA
- Стандарты и организация кода CSS/Sass
- Объектно-ориентированный подход (как объекты разбиваются и собираются вместе)
- JS фреймворки/организация/техники оптимизации производительности
- Доставка активов — Фронтенд операции
- Документация
- Документы по внедрению
- Руководство по стилю/Библиотека шаблонов
- Диаграммы архитектуры (поток кода, цепочка инструментов)
- Тестирование
- Тестирование производительности
- Визуальная регрессия
- Модульное тестирование
- Сквозное тестирование
- Процесс
- Git Workflow
- Управление зависимостями (npm, Bundler, Bower)
- Системы сборки (Grunt/Gulp)
- Процесс развертывания
- Непрерывная интеграция (Travis CI, Jenkins)
-

План проведения интервью по системному дизайну
Перевод репозитория https://leetcode.com/discuss/career/229177/My-System-Design-Template
1. Ожидания от функционала [5 мин]
- Варианты использования
- Сценарии, которые не будут охвачены
- Кто будет использовать
- Сколько пользователей будет
- Шаблоны использования
2. Оценки [5 мин]
- Пропускная способность (QPS для запросов на чтение и запись)
- Ожидаемая латентность системы (для запросов на чтение и запись)
- Соотношение чтения/записи
- Оценки трафика
- Запись (QPS, объем данных)
- Чтение (QPS, объем данных)
- Оценки хранилища
- Оценки памяти
- Какие данные мы хотим хранить в кэше, если используем его
- Сколько RAM и машин нам нужно для достижения этого
- Объем данных для хранения на диске/SSD
3. Цели проектирования [5 мин]
- Требования к латентности и пропускной способности
- Согласованность vs Доступность [Слабая/сильная/итоговая => согласованность | Отказоустойчивость/репликация => доступность]
4. Высокоуровневый дизайн [5-10 мин]
- API для сценариев чтения/записи критических компонентов
- Схема базы данных
- Базовый алгоритм
- Высокоуровневый дизайн для сценариев чтения/записи
5. Глубокое погружение [15-20 мин]
Масштабирование алгоритма
Масштабирование отдельных компонентов:
- Доступность, согласованность и масштабируемость для каждого компонента
- Паттерны согласованности и доступности
Рассмотрение следующих компонентов, их интеграции и пользы:
a) DNS
b) CDN [Push vs Pull]
c) Балансировщики нагрузки [Активный-Пассивный, Активный-Активный, Уровень 4, Уровень 7]
d) Обратный прокси
e) Масштабирование уровня приложений [Микросервисы, Обнаружение сервисов]
f) БД [RDBMS, NoSQL]
- RDBMS
- Мастер-слейв, Мастер-мастер, Федерация, Шардинг, Денормализация, Оптимизация SQL
- NoSQL
- Ключ-Значение, Широкая колонка, Граф, Документ
- Быстрый поиск:
- RAM [Ограниченный размер] => Redis, Memcached
- AP [Неограниченный размер] => Cassandra, RIAK, Voldemort
- CP [Неограниченный размер] => HBase, MongoDB, Couchbase, DynamoDB
g) Кэши
- Клиентское кэширование, CDN кэширование, Кэширование веб-сервера, Кэширование базы данных, Кэширование приложений, Кэш на уровне запросов, Кэш на уровне объектов
- Политики вытеснения:
- Cache aside
- Write through
- Write behind
- Refresh ahead
h) Асинхронность
- Очереди сообщений
- Очереди задач
- Обратное давление
i) Коммуникация
- TCP
- UDP
- REST
- RPC
6. Обоснование [5 мин]
- Пропускная способность каждого уровня
- Латентность между каждым уровнем
- Обоснование общей латентности
-

Числа, которые должен знать каждый разработчик
Времена доступа к памяти и хранилищам
- Обращение к кэшу L1: 0.5 нс
- Обращение к кэшу L2: 7 нс
- Обращение к основной памяти: 100 нс
- Чтение 1 МБ последовательно из основной памяти: 250,000 нс
- Произвольный доступ к жесткому диску: 10,000,000 нс
- Чтение 1 МБ последовательно с жесткого диска: 20,000,000 нс[3]
Эти цифры показывают, насколько критична оптимизация работы с памятью и дисками для производительности программ.
Сетевые задержки
- Пересылка 2 КБ по сети со скоростью 1 Гбит/с: 20,000 нс
- Передача сообщения туда/обратно в одном дата-центре: 500,000 нс
- Передача пакета из Калифорнии в Нидерланды и обратно: 150,000,000 нс[3]
Понимание сетевых задержек важно при разработке распределенных систем.
Другие важные числа
- Ошибка при предсказании условного перехода: 5 нс
- Открытие/закрытие мьютекса: 25 нс
- Сжатие 1 КБ быстрым алгоритмом: 3,000 нс[3]
Эти цифры помогают оценивать эффективность различных операций в коде.
Степени двойки
Разработчикам также полезно помнить степени двойки: 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024[31]. Они часто встречаются при работе с памятью, файловыми системами и другими аспектами разработки.
Коды ошибок HTTP
- 403: доступ запрещен
- 404: страница не найдена
- 500: внутренняя ошибка сервера
- 503: сервис недоступен[31]
-

План проектирования системы (System Design Outline)
Перевод и адаптация этого репозитория https://github.com/jguamie/system-design/blob/master/notes/system-design-outline.md
Это рекомендуемый подход к решению задач проектирования систем. Не все эти темы будут актуальны для конкретной задачи.
- Функциональные требования / Уточнения / Предположения (Functional Requirements / Clarifications / Assumptions)
- Нефункциональные требования (Non-Functional Requirements)
- Согласованность vs Доступность (Consistency vs Availability)
- Задержка (Latency)
- Насколько быстрой должна быть эта система?
- Задержка, воспринимаемая пользователем (User-perceived latency)
- Задержка обработки данных (Data processing latency)
- Безопасность (Security)
- Потенциальные атаки? Как их следует смягчать?
- Конфиденциальность (Privacy)
- PII (Personally Identifiable Information — Персональные данные, позволяющие идентифицировать личность), PCI (Payment Card Industry — Индустрия платежных карт) или другие пользовательские данные
- Целостность данных (Data Integrity)
- Как восстановиться после повреждения или потери данных?
- Соотношение чтения:записи (Read:Write Ratio)
- API (Application Programming Interface — Интерфейс программирования приложений)
- Публичные и/или внутренние API?
- Просты ли API для понимания?
- Как идентифицируются сущности?
- Схемы хранения (Storage Schemas)
- SQL (Structured Query Language — Язык структурированных запросов) vs NoSQL (Not Only SQL — Не только SQL, обозначает нереляционные базы данных)
- Очереди сообщений (Message Queues)
- Проектирование системы (System Design)
- Масштабируемость (Scalability)
- Как масштабируется система? Учитывайте увеличение как объема данных, так и трафика.
- Каковы узкие места? Как их следует устранять?
- Каковы граничные случаи? Что может пойти не так? Предполагая, что они произойдут, как их следует решать?
- Как мы будем проводить стресс-тестирование этой системы?
- Балансировка нагрузки (Load Balancing)
- Автомасштабирование / Репликация (Auto-scaling / Replication)
- Кэширование (Caching)
- Партиционирование (Partitioning)
- Репликация (Replication)
- Непрерывность бизнеса и аварийное восстановление (BCDR — Business Continuity and Disaster Recovery)
- Интернационализация / Локализация (Internationalization / Localization)
- Как масштабироваться на несколько стран и языков? Не предполагайте, что в США используется только английский язык.
-

Вопросы для уточнения функциональных и нефункциональных требований
Этап Вопросы Примеры ответов Уточнение требований Какие основные функции должна выполнять система? Система должна позволять пользователям загружать видео, просматривать их и оставлять комментарии Сколько пользователей будет у системы? Ожидается около 10 миллионов активных пользователей в месяц Какой ожидается рост пользовательской базы? Прогнозируется рост на 20% ежегодно в течение следующих 3 лет Какие основные сценарии использования системы? Загрузка видео, просмотр видео, поиск видео, комментирование Определение масштаба Какой ожидаемый объем данных? Ожидается хранение около 500 ТБ видео и 50 ГБ метаданных Какое соотношение операций чтения к записи? Ожидается соотношение 100:1 чтения к записи Какая ожидаемая пиковая нагрузка на систему? До 100 000 запросов в секунду в пиковые часы Определение API Какие основные API endpoints нужны? /upload, /view, /search, /comment Какие параметры будут у этих API? /view?video_id=123, /search?query=cats Проектирование данных Какая структура данных подойдет для хранения видео? Объектное хранилище для видеофайлов, реляционная БД для метаданных Как организовать индексирование для быстрого поиска? Инвертированный индекс по ключевым словам и тегам видео Масштабирование Как обеспечить высокую доступность системы? Репликация данных, распределение по нескольким дата-центрам Как оптимизировать доставку контента пользователям? Использование CDN для кэширования популярных видео Как масштабировать обработку загрузки видео? Асинхронная обработка через очереди сообщений Дополнительные вопросы Как обеспечить безопасность системы? Шифрование данных, аутентификация пользователей, ограничение доступа Как организовать мониторинг системы? Сбор метрик производительности, логирование ошибок, алерты
Денис Матаков
Блог технического руководителя