-
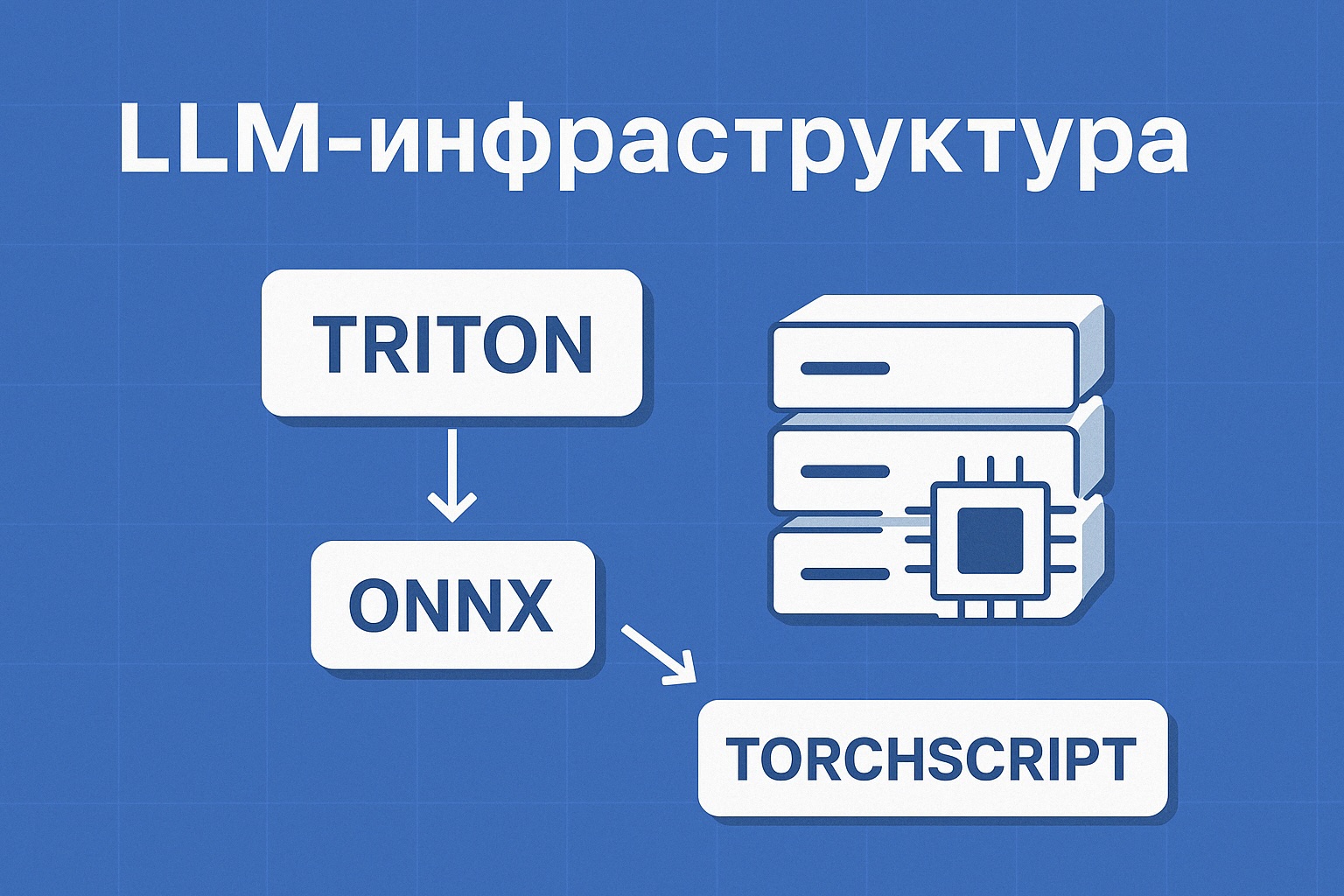
Базовая инфраструктура для запуска LLM: Triton, ONNX, TorchScript и другие
Когда модель готова, важно не только её обучить, но и запустить эффективно, особенно если она используется в проде. Большие языковые модели (LLM) требуют особого подхода к инференсу — и тут приходят на помощь оптимизированные форматы и инференс-серверы.
Что нужно для продакшен-инференса
- Высокая скорость обработки запросов
- Эффективное использование GPU
- Поддержка большого числа одновременных пользователей
- Гибкость и переносимость модели
Обычный
(далее…)pipeline()из Hugging Face удобен, но не масштабируется. Для продакшена нужны другие инструменты. -

Метрики оценки качества моделей
Когда вы обучаете или используете модели машинного обучения и большие языковые модели (LLM), важно измерять их качество. Без метрик невозможно понять, стала ли модель лучше, хуже или осталась такой же.
В этой статье мы рассмотрим:
- Метрики для классификации
- Метрики для генерации текста
- Специальные бенчмарки для LLM
- Как и когда их применять
Классификация: accuracy, F1 и другие
Если модель должна выбрать правильный вариант ответа (например, категорию объявления), используются классические метрики:
- Accuracy — доля правильных ответов
- Precision — точность (насколько предсказанные метки действительно верные)
- Recall — полнота (насколько хорошо модель нашла все правильные ответы)
- F1-score — среднее между precision и recall
-
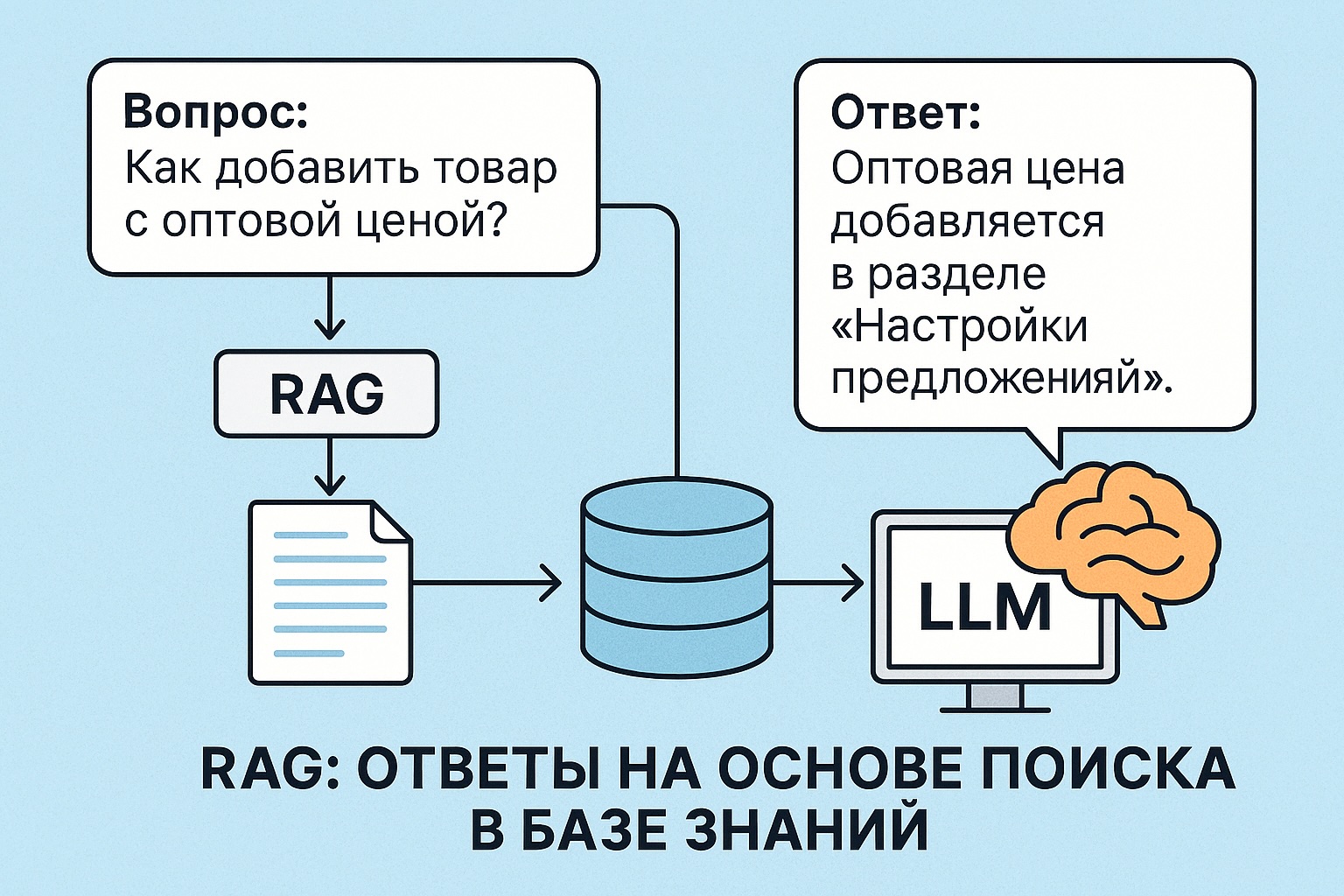
RAG: Ответы на основе поиска в базе знаний
RAG (Retrieval-Augmented Generation) — это подход, при котором большая языковая модель (LLM) получает не только сам вопрос, но и дополнительную информацию из базы знаний. Модель не «вспоминает» ответ из своей памяти, а «читает» найденный текст и отвечает на основе него.
Зачем нужен RAG
LLM не знает ничего о ваших внутренних документах, продуктах или инструкциях. Она может галлюцинировать — выдумывать ответы.
RAG позволяет использовать актуальные и точные данные:
- Вы передаёте в модель текст, найденный по запросу
- Модель отвечает с опорой на этот текст
Как работает RAG
- Получаем вопрос от пользователя
- Кодируем его в вектор (эмбеддинг)
- Ищем похожие документы в базе (векторный поиск)
- Склеиваем найденные тексты и добавляем к вопросу
- Передаём всё это в LLM как prompt
- Модель отвечает
-

Трекинг экспериментов с MLflow и DVC
При разработке моделей важно не только обучить модель, но и уметь:
- отслеживать параметры обучения
- сохранять метрики (точность, F1 и др.)
- версионировать модели и датасеты
- воспроизводить эксперименты
Для этого используются инструменты вроде MLflow и DVC.
Зачем нужен трекинг
Допустим, вы обучили три модели с разными параметрами. Какая из них лучше? Сколько эпох было? Какой
learning_rate? Где лежит файл модели?Без трекинга это всё теряется в коде и папках. С трекингом — у вас есть история всех запусков и чёткая структура.
(далее…) -
Обучение больших моделей с помощью QLoRA
QLoRA — это метод, который позволяет дообучать большие языковые модели (LLM) в сжатом 4-битном виде, экономя память и ресурсы. Он позволяет запускать fine-tuning даже на одной видеокарте вроде RTX 3060 или 3090.
В этой статье разберёмся:
- Что такое QLoRA
- Как она работает
- Когда и зачем её использовать
- Как на практике дообучить свою модель с помощью QLoRA
Что такое QLoRA
QLoRA (Quantized LoRA) сочетает два подхода:
- Квантование — уменьшает размер модели, переводя её веса в 4-битный формат (вместо 16 или 32 бит)
- LoRA (Low-Rank Adapters) — позволяет добавлять к модели небольшие обучаемые адаптеры, не изменяя сами веса модели
-

vLLM: Ускоренный инференс языковых моделей
vLLM — это фреймворк для высокоэффективного запуска больших языковых моделей (LLM), разработанный с нуля для максимальной скорости, параллельности и поддержки большого количества запросов одновременно.
Если вы используете LLaMA, Mistral, Falcon или другие большие модели в проде или прототипе — vLLM это то, что стоит попробовать.
Что делает vLLM особенным
vLLM оптимизирован для инференса LLM. В отличие от стандартного подхода через Hugging Face
pipeline(), он:- поддерживает OpenAI-совместимый API
- эффективно управляет памятью (через PagedAttention)
- обрабатывает десятки и сотни запросов одновременно
- совместим с популярными моделями
-

Hugging Face Transformers: Пошаговое введение
Transformers — это библиотека от Hugging Face, которая позволяет легко использовать мощные языковые модели вроде BERT, GPT, RoBERTa и многих других. Она содержит как сами модели, так и удобные инструменты для инференса, обучения и обработки текста.
В этом материале:
- Что такое pipeline и как быстро сделать инференс
- Как загружать модели и токенизаторы вручную
- Как обучить модель под свою задачу (fine-tuning)
- Как сохранить и использовать свою модель
-
PyTorch: Пошаговое введение
PyTorch — это популярная библиотека для построения и обучения нейросетей. Она используется как в академии, так и в индустрии, потому что сочетает в себе мощь, гибкость и простоту.
В этом материале мы рассмотрим:
- Что такое тензоры и как с ними работать
- Как работает автодифференцирование
- Как писать собственные модели
- Как обучать модель шаг за шагом
-

Первый взгляд на Google Firebase Studio
Что это такое
Google выпустил новый инструмент под названием Firebase Studio — веб-приложение для программирования с интеграцией ИИ (на базе Gemini 2.5). Оно умеет:
- редактировать файлы;
- запускать команды;
- и, в целом, пытается быть полноценным агентом для разработки прямо в браузере.
На первый взгляд — это что-то вроде веб-версии VS Code с интеграцией ИИ от Google. Но есть нюансы.
Интерфейс и UX
Главное, что бросается в глаза — необычное расположение чата с ИИ. Вместо привычной правой панели он расположен в виде отдельной вкладки рядом с файлами. Это непривычно и сбивает с толку.
Интерфейс в целом оставляет желать лучшего: низкая отзывчивость, частые подвисания, неудобная навигация. Чтобы применить изменения, часто приходится перезапускать Android-эмулятор целиком — интерфейс сам не обновляется.
Тест-драйв: вайб-кодинг
Я решил протестировать Firebase Studio в стиле вайб-кодинга — использовать стек, в котором почти не разбираюсь. В качестве цели выбрал простое мобильное приложение на React Native.
Через 40 минут у меня так и не получилось собрать работающее приложение. Сначала оно падало с ошибкой 500. Как бы я ни просил ИИ «починить» проект, он ходил по кругу и не предлагал рабочее решение.
Пришлось самому прочитать ошибку, зайти в нужный файл и поправить код вручную. Ошибка оказалась несложной — я справился без опыта в React Native. Но для ИИ это оказалось непреодолимой задачей.
После исправления мы с агентом ещё около получаса дописывали логику, добавляли меню и кнопки. Но ощущение нативности так и не появилось — всё выглядело скорее как веб-приложение в эмуляторе, а не полноценный Android-интерфейс.
Проблемы с производительностью
Ещё один важный минус — общая медлительность. Интерфейс реагирует с задержками, некоторые кнопки не работают, а при падении приложения исправления не применяются без перезапуска эмулятора. Навигация по вкладкам помогает лишь частично.
Альтернатива: VS Code и Cursor
Пока что Firebase Studio — это больше эксперимент, чем готовый инструмент. Для целей вайб-кодинга он пока не годится.
Тем временем конкуренты не стоят на месте. Например, VS Code получил обновление: теперь он тоже умеет запускать команды через ИИ, как это делает Cursor. Таким образом, VS Code и Cursor становятся прямыми конкурентами — и это отличная новость для всех, кто интересуется AI-помощниками для разработки.
Вывод
Firebase Studio — интересный шаг от Google, но в текущем виде он скорее разочаровывает. У Google ещё есть время довести интерфейс до ума и улучшить работу ИИ. А пока — рекомендую продолжать использовать более зрелые решения.
-

Жизнь под контролем версий: как Git может спасти ваш конфиг, резюме и не только
Обычный вечер и немного .bak
Вчера я залез в конфиги своего роутера. Роутер на Linux, конфиги в виде файлов, всё как у людей. Прежде чем что-то менять — делаю бэкап. Просто копирую файл и добавляю
.bakв конец. Иногда выходитconfig.bak, потомconfig.bak2,config.bak_final,config.bak_final2_really… Думаю, у многих такая же история.В какой-то момент я понял: это же полнейший бардак. И главное — зачем всё это, если у нас есть Git?
Репозиторий на роутере — почему бы и нет
Решение пришло само собой: я инициализировал Git-репозиторий прямо на роутере. Удалил все .bak-файлы, сделал первый коммит и начал экспериментировать. Что-то сломал — спокойно откатился. Заработало как надо — сделал новый коммит. Всё просто и прозрачно.
И вот тут в голове щёлкнуло: почему я не делаю так везде?
Git как способ мышления
Сейчас я работаю над резюме. Постоянные правки, новые формулировки, добавления, удаления. До этого всё шло в один файл, и если я что-то «переигрывал», то часто терял предыдущий вариант. А теперь у меня есть репозиторий с историей изменений. Можно вернуться, посмотреть, как развивались мысли, какие достижения вспоминались, какие формулировки оказались лучше.
И это безумно удобно.
Мир больше, чем код
Git — это не только про код. Это про мышление. Про контроль над изменениями. Про возможность безопасно экспериментировать и видеть историю своих действий. У нас в руках мощный инструмент, который легко переносится на любую работу с текстом.
Где ещё можно использовать Git?
— В личных заметках
— В черновиках статей или постов
— В резюме и портфолио
— В планах обучения
— В подготовке к публичным выступлениям
— Даже в договорённостях по проектам (если вы технарь, конечно)Всё, что можно представить как «файл с изменениями», можно завернуть в репозиторий.
Хаос против структуры
Мир не делится на «код» и «не код».
Мир делится на хаос и репозитории.
Денис Матаков
Блог технического руководителя