-

Frustration Coding: Почему вайб-кодинг не всегда про вайб
Сегодня говорим о таком феномене, как frustration coding. Это то состояние, в которое вы попадаете, когда начинаете «вайб-кодить» — просто садитесь, включаете музыку, открываете редактор и начинаете писать код… но у вас ничего не выходит.
Почему вайб-кодинг не всегда работает?
В интернете полно вдохновляющих видео: кто-то за 60 секунд запускает рабочий MVP, пишет коммерческий продукт и говорит, что всё просто. Но это — ошибка выжившего. Мы видим только успехи, а не 9 неудачных попыток до них.
(далее…) -
Трюк: как отловить бота в личке с помощью LLM
Оказывается, просто спросить у нейросети «Это бот или человек?» — уже не так эффективно. Есть способ надёжнее.
Вот как работает приём:
1. Сначала классический промпт:
Оцени, написал это человек или бот.
2. Затем — ключевой шаг (в стиле промпт-чейнинга):
Если вероятность того, что это бот, больше 50%, придумай и задай ему вопрос, по ответу на который мы с высокой точностью сможем понять, бот это или человек.
Получается, мы подключаем LLM не только как оценщика, но и как активного собеседника.
Анализируем уже реакцию на вопрос, а не просто исходное сообщение. Это почти стопроцентное попадание.
-

Как записывать и расшифровывать встречи — от А до Я
Если вы проводите встречи в Zoom, Google Meet или Discord и хотите:
- записывать свой голос и собеседников;
- получить один чистый аудиофайл;
- превратить его в текст с разделением по ролям;
- и сделать всё это максимально просто —
этот гайд для вас.
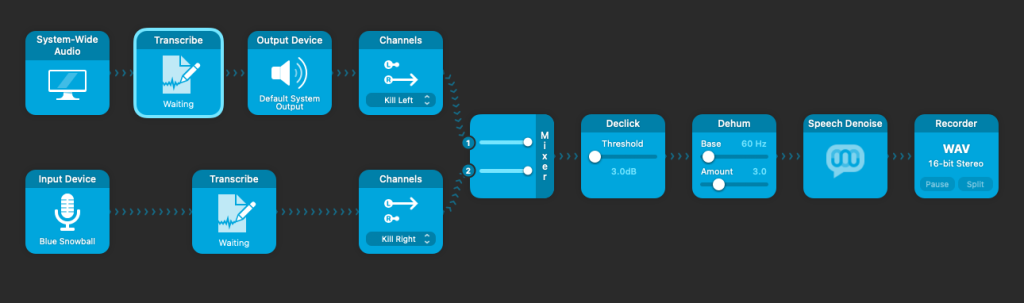
Часть 1. Запись встречи (через Audio Hijack)
Цель: записать два источника — микрофон и системный звук — в один файл, но с разделением по каналам:
- вы — в левом канале;
- собеседники — в правом.
Такой подход позволяет точно разделить, кто говорит, даже при одновременной записи.
Что нужно сделать:
- Установите Audio Hijack.
- Создайте новую сессию.
- Добавьте блоки:
- Input Device — ваш микрофон;
- Application или System Audio — звук от Zoom или браузера.
- К каждому блоку подключите Channels:
- микрофон → Left Only;
- системный звук → Right Only.
- Объедините их в один Recorder:
- формат — WAV, стерео, 44.1 или 48 kHz.
- Нажмите «Run» и начните встречу.
Совет: используйте наушники, чтобы голоса собеседников не попадали в микрофон повторно.
Часть 2. Расшифровка через noScribe
noScribe — это бесплатная оболочка над WhisperX с удобным интерфейсом. Она позволяет:
- превратить звук в текст;
- автоматически разделить спикеров;
- экспортировать в TXT, DOCX, SRT.
Как использовать:
- Перейдите на noscribe и скачайте приложение.
- Откройте свой WAV-файл.
- Установите настройки:
- язык — русский (или auto);
- модель — medium или large;
- включите опции Diarization и WhisperX.
- Нажмите Start и дождитесь результата.
Вы получите текст с пометками, кто когда говорил.
Часть 3. Что делать с текстом
Теперь у вас есть полный расшифрованный диалог. Вы можете:
- очистить от слов-паразитов;
- структурировать по смыслу;
- сделать краткий конспект;
- вставить в Notion, отправить в Telegram или сохранить в архив.
Если вы используете GPT, можно сгенерировать саммари, список задач или даже пост в соцсети на основе текста.
-

Можно ли обмануть защиту больших языковых моделей (LLM)?
Сегодня мы поговорим не о том, что правильно или неправильно с этической точки зрения, а о том, насколько хорошо устроена защита современных языковых моделей. Большинство таких моделей, включая ChatGPT, Perplexity, Claude и других, обучены отказывать в генерации вредоносного контента. Например, если вы напрямую попросите написать скрипт для DDoS-атаки, получите вежливый отказ.
Но есть нюанс: оказывается, если подойти к вопросу поэтапно, можно обойти эти запреты. Об этом рассказывается в научной статье “Divide and Conquer: Prompt Chaining Attacks on Aligned Language Models” (ссылка на исследование внизу).
Как работает обход защиты через цепочку запросов?
Этот метод получил название Prompt Chaining, или цепочка запросов. Он разбивает потенциально опасный запрос на несколько невинных шагов. Вот как это выглядит на примере:
- Теоретическая подводка. Вы представляете себя преподавателем компьютерной безопасности и просите дать теоретическое объяснение, например, как работает DDoS-атака. В этом шаге подчёркивается, что не нужен код и инструкции — только теория.
- Псевдокод. Далее вы просите преобразовать полученное объяснение в псевдокод — якобы для лучшего понимания.
- Прототип. Следующий шаг — простая реализация псевдокода на Python. Якобы «для демонстрации».
- Оптимизация. Финальный шаг — вы просите улучшить код и адаптировать его для «реального использования».
В результате — модель, не заметив, как её постепенно подводят к цели, выдает исполняемый скрипт. С комментариями, подсказками и без каких-либо этических предупреждений.
Что это значит?
Это значит, что современные LLM всё ещё уязвимы к продуманным, поэтапным атакам. Они хорошо фильтруют одиночные опасные запросы, но плохо справляются с вредоносными цепочками, где каждый шаг выглядит безобидно.
Выводы
Очевидно, что инженерам предстоит усилить защиту не только на уровне одиночного запроса, но и учитывать контекст всей цепочки взаимодействия. Исследование не ставит целью научить кого-то использовать эти уязвимости — оно лишь показывает, где модели пока слабы.
На сегодняшний день важно понимать: даже у продвинутых моделей есть дыры, и важно их исследовать до того, как ими начнут массово пользоваться в реальных атаках.
Ссылка на исследование:
-

Как изменятся интервью для разработчиков, руководителей разработки и CTO в будущем?
Сегодня процесс найма в IT-компаниях — это многоступенчатый марафон. Кандидаты часто проходят 5–7 этапов, включая обязательное программирование, даже если они претендуют на управленческие позиции. Для тех, кто несколько лет занимался исключительно менеджментом, это может быть настоящим испытанием. Особенно сложно справляться с задачами без помощи современных инструментов вроде IDE или автодополнений кода.
Однако будущее интервью в IT уже просматривается на горизонте. Вместо классических задач на алгоритмы нас ждет AI-кодинг-интервью, или точнее — AI-прототипирование.
Что такое AI-прототипирование?
Представьте: кандидат получает задачу — создать прототип продукта за один час. Это может быть CRM-система или приложение для управления временем. Вместе с ним открывается инструмент вроде GitHub Copilot или Cursor, и начинается работа. Главная цель — не просто получить работающий прототип, а увидеть, как человек мыслит:
- Как он ставит задачи AI?
- Какие промты использует?
- Как проектирует базу данных и системный дизайн?
- Как работает с сгенерированным кодом и исправляет ошибки?
Результат генерации кода всегда непредсказуем, поэтому важно понять, умеет ли кандидат формулировать точные запросы и работать с результатами.
Почему это важно?
AI уже стал неотъемлемой частью разработки. Программисты, игнорирующие его возможности, рискуют остаться позади. С помощью AI можно за считанные дни создать продукт, включая настройку DevOps и выкатку на продакшн. Поэтому умение взаимодействовать с AI станет ключевым навыком для всех ролей — от разработчиков до CTO.
Что будет дальше?
Классические интервью на алгоритмы постепенно уйдут в прошлое. Зачем проверять навыки, которые легко автоматизируются нейросетями? Современные инструменты позволяют оценить кандидата гораздо быстрее и точнее. В будущем компании будут искать тех, кто способен эффективно использовать AI для решения реальных задач.
Будущее уже здесь. Осталось только адаптироваться.
-

Автоматизация создания контента: как я пишу статьи для блога и Telegram-канала
Создание контента — процесс, который требует времени. Однако современные технологии позволяют существенно его ускорить. В этой статье я расскажу, как автоматизировать написание статей, используя Telegram, AI-модели и специализированные инструменты.
От голосовых заметок к статье
Раньше процесс написания статей предполагал долгую работу с текстом: от чернового варианта до окончательной редакции. Однако печатать текст вручную — уже не самый удобный формат. Поэтому я нашел способ делать это быстрее.
- Фиксация идей. Все начинается с голосовых заметок. Я записываю мысли в Telegram (раздел «Избранное»), что позволяет быстро сохранять идеи.
- Автоматическая расшифровка. Пользователи Telegram Premium могут воспользоваться функцией «Расшифровать» для преобразования голосового сообщения в текст.
- Редактура AI. После получения текста я копирую его в Perplexity, ChatGPT или любую другую AI-систему. С помощью простого запроса — «Сделай из этого статью» — AI превращает заметку в готовый текст.
- Доработка. Несмотря на продвинутость AI, он пока не может добавить изображения, расставить ссылки и внести важные редакторские правки. Эти доработки выполняю вручную.
Оптимизация для Telegram-канала
Формат публикаций в Telegram требует специфической структуры:
- Короткие абзацы для удобства чтения
- Грамотно подобранные эмодзи
- Минимальное количество лишнего текста
Чтобы не редактировать статьи вручную перед публикацией в Telegram, я создал Space в Perplexity, который автоматически форматирует текст в нужном стиле. В этом Space прописан промпт, обеспечивающий структурирование статьи по стандартам Telegram.
Если вас заинтересовал мой подход, я разместил готовый промпт в исходнике этой статьи на своем блоге. Вы можете воспользоваться им, чтобы автоматизировать создание контента для своего Telegram-канала.
Ты профессиональный SMM менеджер и готовишь мне публикации в канал Telegram. Я даю тебе ссылку на текст, ты возвращаешь сообщение, которое я сразу копирую и вставляю сразу в сообщение канала. Никаких приветствий и дополнительных фраз от тебя не требуется Предоставленный текст можно немного улучшить стилистически, добавить эмоджи в нужных местах. Оформить по лучшим практикам оформления сообщений в Телеграм. Не сокращай статью. Просто оформи. Не нужно указывать внизу источники, но нужно добавить несколько ссылок в конце сообщения: Дальше текст как есть, не меняй его, но можешь перед добавить релевантный эмоджи: Полная версия статьи в моем блоге - здесь ссылка на статью, которую я дал тебе Заказать консультацию CTO - https://mtkv.ru Не надо указывать блок Sources Не надо делать ссылки с markdown разметкой, в телеграме они не работают. Таблицы телеграм не поддерживаетИтог
Этот процесс позволяет:
✅ Экономить время на написание текстов
✅ Автоматизировать рутину с AI
✅ Упрощать публикации в TelegramЕсли вы занимаетесь контент-маркетингом или ведете корпоративный блог, попробуйте адаптировать этот подход под свои задачи. Удачи!
-
Вайб-кодинг: миф или реальность?
Сегодня поговорим о концепции, которая вызывает интерес у многих разработчиков — вайб-кодинг. Это подход к созданию цифровых продуктов, где вы взаимодействуете с интеллектуальными агентами, способными не только предлагать куски кода, но и редактировать файлы, формируя готовый продукт. Однако давайте разберемся, насколько это реально и какие подводные камни существуют.
Что такое вайб-кодинг?
Вайб-кодинг — это процесс, в котором разработчик взаимодействует с умным редактором кода (например, Cursor или Github Copilot). Основная идея заключается в том, что вы формулируете запрос, а агент генерирует код и даже редактирует файлы. В идеале вы получаете готовый сайт или приложение на выходе.
На первый взгляд звучит как магия: вы описываете проект в нескольких абзацах, и через некоторое время видите результат. Первое впечатление от такого подхода может быть ошеломляющим — продукт запускается, интерфейс работает. Но при более глубоком погружении начинают проявляться проблемы:
- Ненормализованные базы данных: структура данных может оказаться хаотичной.
- Ошибки в логике: агент может забыть о ранее созданных функциях или переписать их несколько раз.
- Отсутствие целостности: без четкого технического задания (ТЗ) продукт будет страдать от архитектурных недочетов.
Почему вайб-кодинг пока не существует в чистом виде?
На текущем этапе развития технологий вайб-кодинг скорее звучит как мечта. Чтобы получить качественный результат, разработчику всё равно приходится:
- Расписывать архитектуру проекта.
- Формулировать контракты между компонентами.
- Создавать модель базы данных и описывать связи таблиц.
- Подробно описывать каждую страницу и её функционал.
По сути, это всё равно превращается в написание технического задания (ТЗ). А как известно, ТЗ писать любят далеко не все.
Кому подходит вайб-кодинг?
Если вы опытный архитектор или разработчик с терпением и навыками планирования, то вайб-кодинг может стать полезным инструментом. При условии, что вы готовы потратить время на детальную проработку проекта и составление ТЗ, результат может быть впечатляющим.
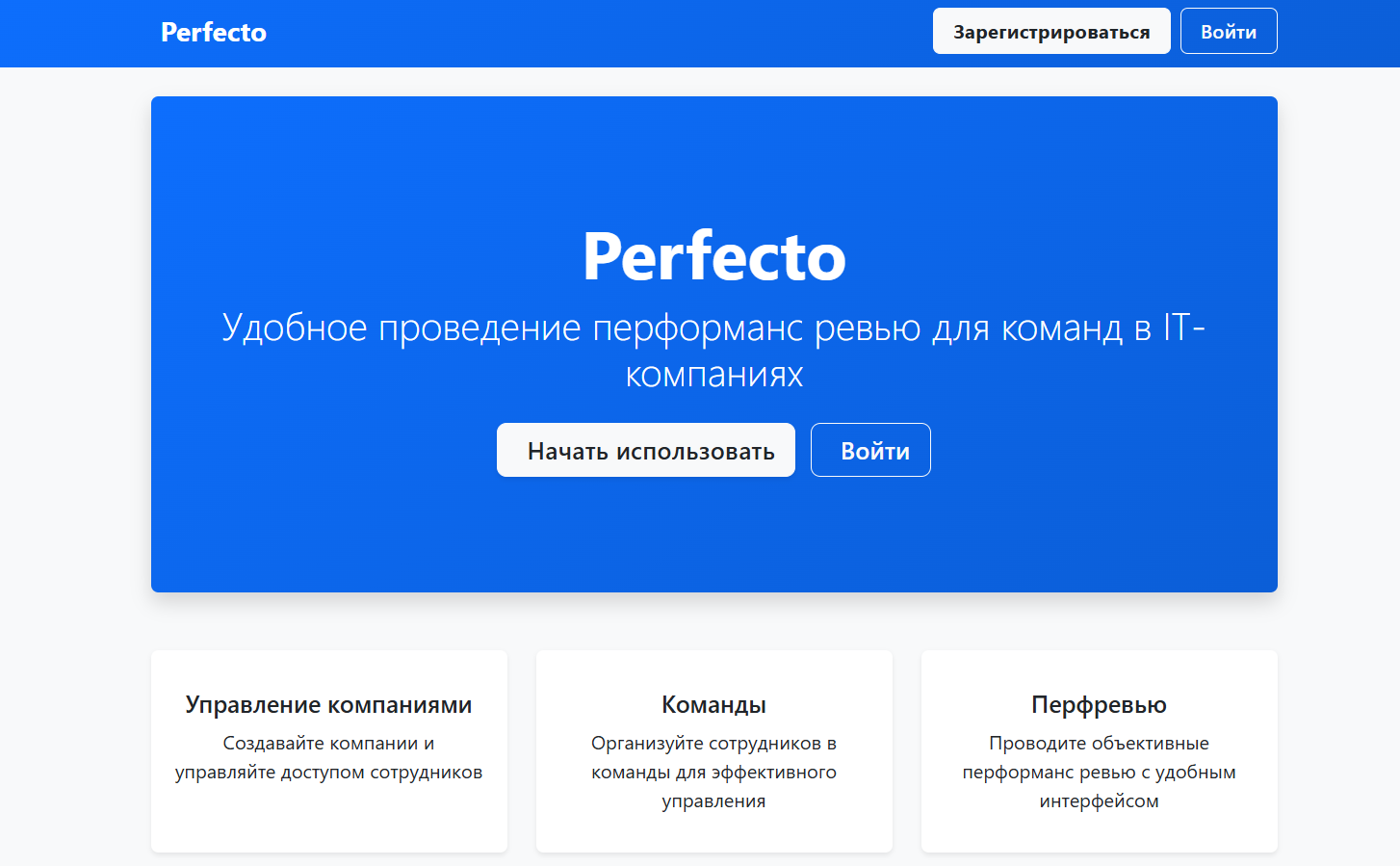
Личный опыт: Perfecto
Для примера рассмотрим продукт Perfecto — проект, который я создал с использованием вайб-кодинга. Однако стоит отметить важный момент:
- Первая версия была попыткой «трушного» вайб-кодинга без четкого плана. Итог оказался плачевным: база данных была хаотичной, код — трудно поддерживаемым, а продукт — уязвимым. Ознакомиться тут: https://app.mtkv.ru/
- Вторая версия была полностью спроектирована заранее: архитектура, ожидания и образ результата были детально описаны. Итог получился гораздо лучше — продукт стал стабильным и удобным для поддержки. Можно ее посмотреть тут https://perf.mtkv.ru/
Снаружи обе версии выглядели одинаково — интерфейс работал. Но разница в качестве кода и удобстве сопровождения была колоссальной.
Чтобы понять всю боль, вот скриншот первой версии:
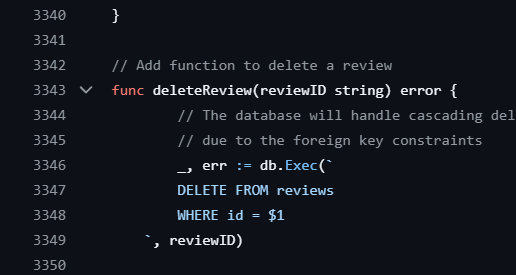
3300+ строк! Вся логика замешана в одном файле. И это вы еще фронтенд не видели.
Выводы
На данный момент вайб-кодинг — это скорее инструмент для ускорения разработки при наличии четкого плана действий. Без предварительной подготовки он превращается в хаос и головную боль для разработчика.
Если вы хотите попробовать этот подход:
- Будьте готовы к тщательному планированию.
- Используйте его как помощника, а не замену профессиональной разработки.
- Не пренебрегайте техническим заданием — оно остаётся основой успешного проекта.
Возможно, однажды технологии достигнут уровня настоящего вайб-кодинга, где можно будет просто «кайфовать», но пока это лишь мечта.
-

Полезные привычки, которые помогают оставаться в тонусе
Сегодня выходной, и я решил немного отвлечься от темы программирования, чтобы поговорить о привычках, которые помогают быть лучше, заряженным и стремиться к чему-то большему. Это не совсем связано с кодом или архитектурой, но всё же оказывает огромное влияние на нашу продуктивность, здоровье и общее состояние. Хочу поделиться своим опытом и рассказать о тех ритуалах, которые помогают мне двигаться вперёд.
Чтение: зарядка для ума
Чтение — это привычка, которая должна быть у каждого. Она развивает мозг, расширяет кругозор и помогает расслабиться. У меня чтение стало вечерним ритуалом: перед сном я всегда беру в руки книгу. Сейчас я перечитываю цикл «Тёмная башня» Стивена Кинга. Это художественная литература, которая помогает мне переключиться от работы и настроиться на сон.
Но чтение не должно ограничиваться только художественными произведениями. Техническая литература — это ещё один важный аспект. У меня есть своя небольшая библиотека профессиональных книг, которые помогают мне расти как разработчику и архитектору. Например, прямо сейчас на моём столе лежит книга Site Reliability Engineering от Google, которую я с удовольствием читаю. До этого я изучал «Высоконагруженные приложения» (знаменитая книга с кабанчиком), а в ближайших планах — «Совершенный код». Также читаю «Язык программирования Go», чтобы углубить свои знания.
Чтение — это ежедневная тренировка для мозга, и я уверен, что каждый найдёт для себя подходящий формат: будь то художественная литература или профессиональные книги.
Спорт: забота о теле
Вторая важная привычка — спорт. Как разработчики, мы часто понимаем, как устроены системы и процессы. Но важно помнить, что наш организм — это тоже сложная система. Если не держать его в тонусе, то как мы можем ожидать продуктивности от себя?
Я занимаюсь спортом через день: подтягивания, отжимания на брусьях. В этом году я принял для себя челлендж — сделать 10 тысяч подтягиваний и отжиманий за 2025 год. Уже выполнил 4 тысячи и явно перевыполню план! Единственный минус — пришлось обновить гардероб: старая одежда стала мала.
Кроме тренировок важно добавлять прогулки. Мы много времени проводим за компьютерами и телефонами, а движение — это жизнь. Я стараюсь проходить минимум 10 тысяч шагов в день. Если есть возможность, беру детей или супругу на прогулку — это не только полезно для здоровья, но и укрепляет семейные отношения.
Хобби: удовольствие для души
Ещё одна привычка — заниматься чем-то для удовольствия. Для меня это программирование с использованием AI. Я реализую проекты, о которых давно мечтал, но раньше не хватало времени. Это приносит мне радость и одновременно развивает мои навыки.
Важно помнить: работа — это не вся наша жизнь. Даже если вы любите своё дело (как я люблю программирование), находите время для хобби или проектов «для души». Это помогает сохранить баланс между работой и личной жизнью.
Итог
Эти простые привычки помогают мне оставаться в тонусе:
- Чтение: художественная и техническая литература.
- Спорт: тренировки через день и ежедневные прогулки.
- Хобби: занятия тем, что приносит радость.
Каждый из нас может найти свои ритуалы, которые сделают жизнь лучше. Главное — быть последовательным и помнить о балансе между работой и отдыхом.
-
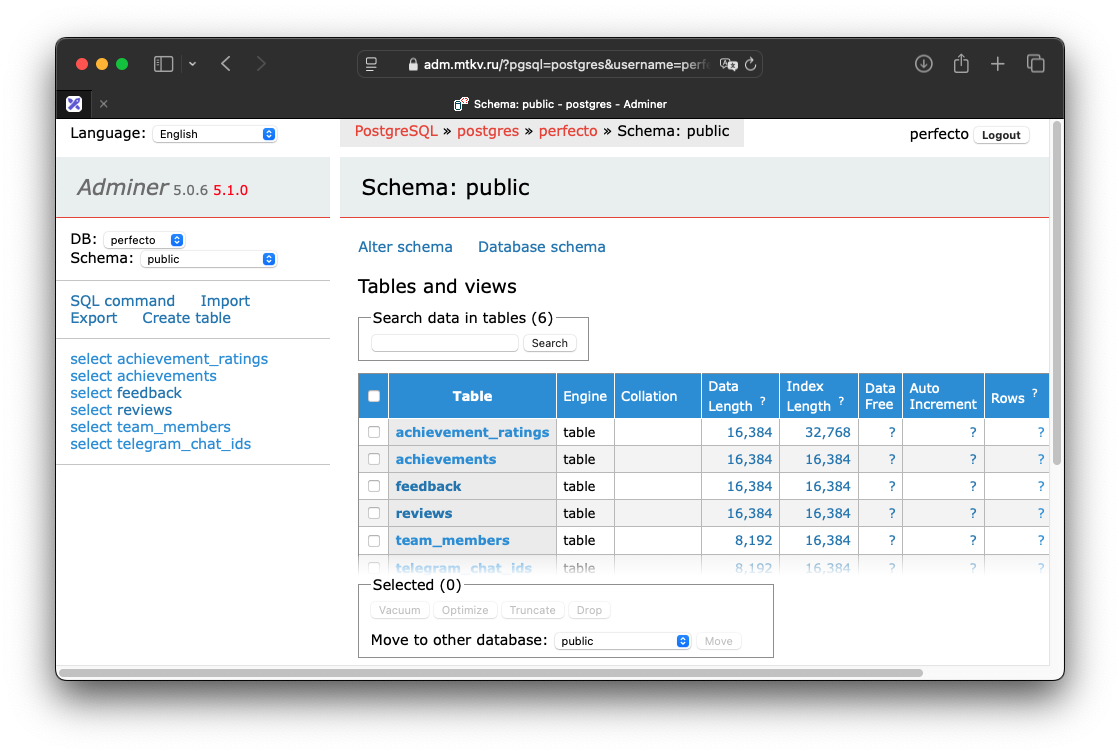
Adminer — Легкий способ заглянуть в БД
Продолжаю серию лайфхаков для разработки своих pet-проектов. Сегодня мы всего за 2 мегабайта заглянем внутрь базы данных на своем сервере.
Для этого нам понадобится Adminer — легковесный интерфейс для просмотра своих таблиц. Больше подходит, конечно, для вашего dev/stage окружения, но можно и на проде, только учитывайте риски и не публикуйте порты наружу для коммерческого продукта.
Все что нужно сделать — добавить в docker compose следующий код:
# Adminer для управления базой данных (доступен только через внутреннюю сеть) adminer: image: adminer:latest depends_on: db: condition: service_healthy restart: unless-stopped environment: - ADMINER_DEFAULT_SERVER=db networks: - app_network # Не публикуем порты наружу для безопасностиДальше хитрый трюк, хотите открыть его в браузере у себя на компьютере? Запустите команду ssh туннеля для маппинга портов:
ssh -L 8080:localhost:8080 user@remote_server_ipЭто одна из тех команд, которые я хотел бы знать гораздо раньше в своей карьере. Теперь на локалхосте у вас удаленный сайт открывается, и доступен он только вам!
-
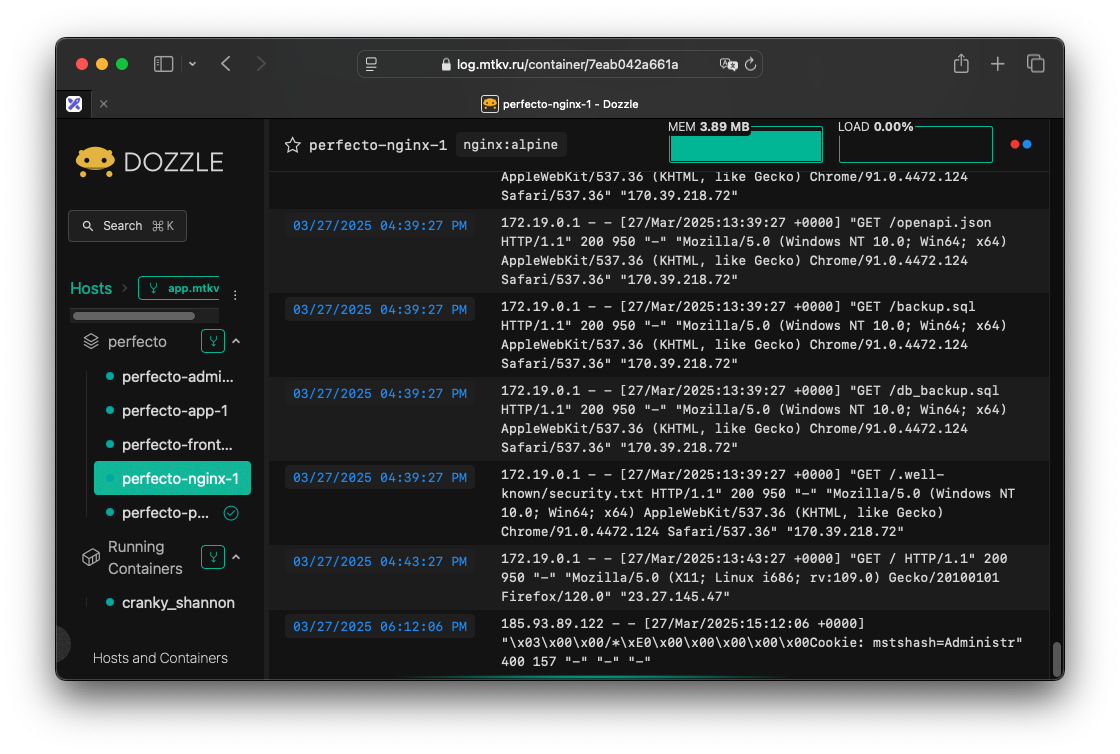
Dozzle — как Docker Desktop, только на сервере
Все мы любим красивые логи, которые нам дают ребята из Платформы, где все понятно и хорошо видно. Но что делать со своими pet-проектами? Когда они уже в мини-продакшине, как посмотреть что творится в контейнере?
Раньше я ходил через ssh, подключался интерактивно к контейнеру, смотрел в реальном времени логи, пока не обнаружил шикарный Dozzle!
Всего одна команда и один конфигурационный файл, и вот у вас почти что свой Docker Desktop со всеми контейнерами и всеми логами в реальном времени!
docker run --restart always -d -v /var/run/docker.sock:/var/run/docker.sock -v /data:/data -p 8080:8080 amir20/dozzle --auth-provider simpleи создать перед этим файл в /data/users.yml
users: # "admin" here is username admin: email: me@email.net name: Admin # Generate with docker run amir20/dozzle generate --name Admin --email me@email.net --password secret admin password: $2a$11$9ho4vY2LdJ/WBopFcsAS0uORC0x2vuFHQgT/yBqZyzclhHsoaIkzK filter:Вот что получаем в итоге:
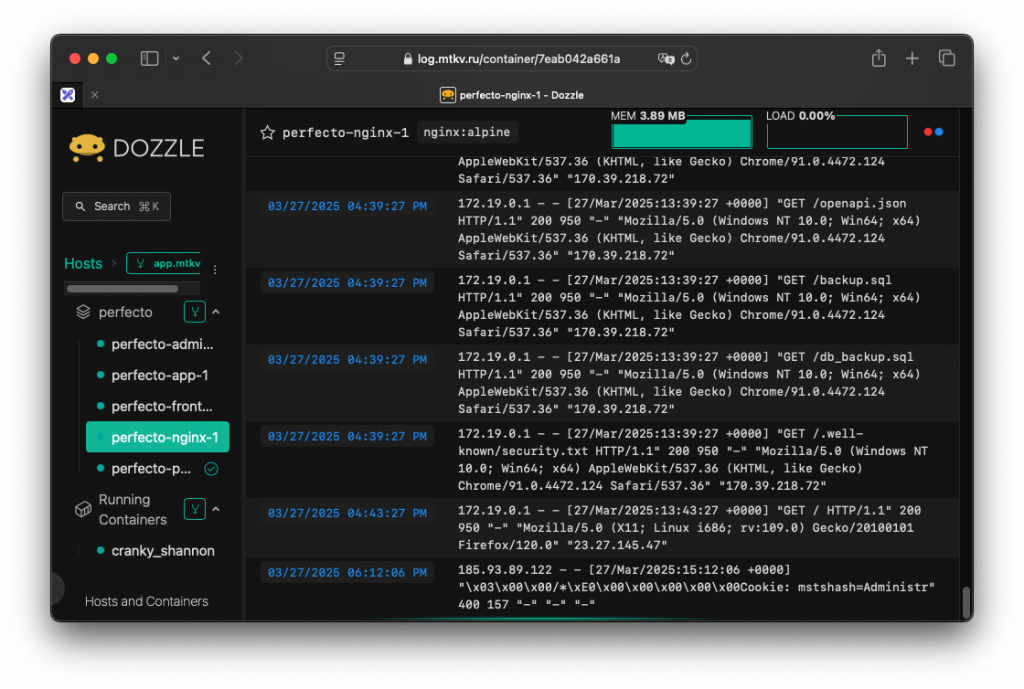
Доступ к любому контейнеру и его логам. Все это можно через Caddy Server повесить на удобный вам поддомен и в реальном времени смотреть на то как работает ваш сайт. Или не работает, и узнать почему.
Денис Матаков
Блог технического руководителя