Для проведения интервью можно использовать следующий шаблон — позволяет структурировать ответ и не забыть спросить основные моменты, необходимые для проектирования:
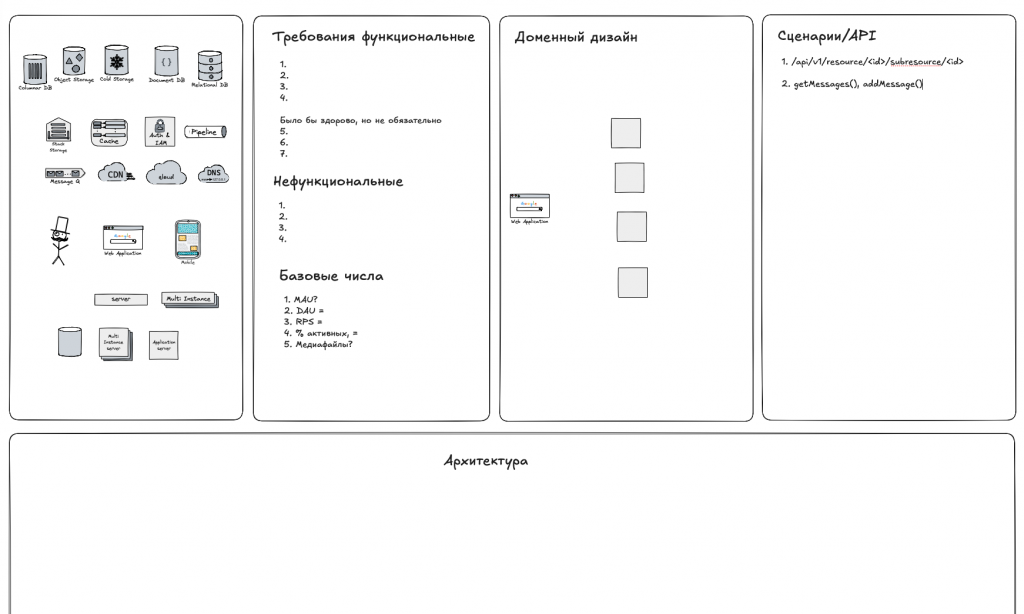
Скачать шаблон для https://excalidraw.com/
Блог технического руководителя
Присоединяйтесь к моему телеграм-каналу CTO Лайфхаки
Подробнее о моих услугах для бизнеса
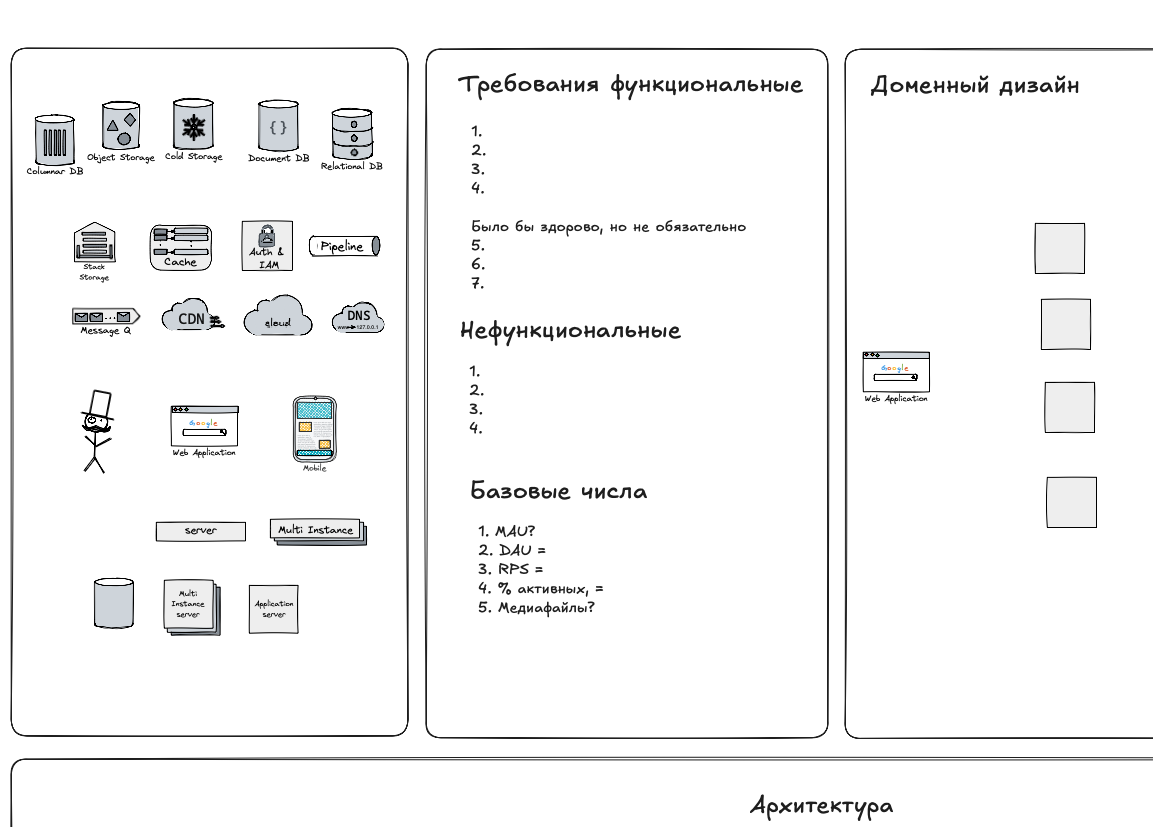
Для проведения интервью можно использовать следующий шаблон — позволяет структурировать ответ и не забыть спросить основные моменты, необходимые для проектирования:
Скачать шаблон для https://excalidraw.com/

Количество WebSocket-соединений, которые можно открыть на одном чат-сервере, зависит от нескольких факторов, но теоретически это число может быть очень большим. Рассмотрим основные аспекты:
Теоретически, максимальное количество WebSocket-соединений на одном сервере может достигать огромных значений. Каждое соединение уникально идентифицируется комбинацией IP-адреса клиента и порта источника. Это означает, что теоретический предел составляет около 2^48 (примерно 281 триллион) соединений на один порт сервера.
На практике количество соединений ограничивается несколькими факторами:
Для поддержки большого числа WebSocket-соединений рекомендуется:
В заключение, хотя теоретически возможно открыть миллионы WebSocket-соединений на одном сервере, практическое количество будет зависеть от конкретной конфигурации оборудования, оптимизации программного обеспечения и требований к производительности вашего чат-приложения. Для большинства реальных сценариев использования чат-сервер может эффективно обслуживать тысячи или даже десятки тысяч одновременных WebSocket-соединений при правильной настройке и оптимизации.

| Фреймворк | Язык | RPS | Удобство | Экосистема | Сообщество | Документация | Масштабируемость | Безопасность | Интеграция |
|---|---|---|---|---|---|---|---|---|---|
| Actix | Rust | 100000 | 7 | 7 | 8 | 8 | 9 | 9 | 7 |
| Warp | Rust | 90000 | 7 | 6 | 7 | 7 | 9 | 9 | 7 |
| ASP.NET Core | C# | 60000 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
| Fiber | Go | 60000 | 8 | 7 | 8 | 8 | 8 | 8 | 8 |
| Gin | Go | 55000 | 8 | 8 | 9 | 8 | 8 | 8 | 8 |
| Fastify | JS | 60000 | 9 | 8 | 8 | 9 | 8 | 8 | 9 |
| NestJS | JS | 50000 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
| Spring Boot | Java | 40000 | 8 | 10 | 10 | 9 | 10 | 9 | 10 |
| Micronaut | Java | 35000 | 8 | 8 | 7 | 8 | 9 | 9 | 8 |
| FastAPI | Python | 30000 | 9 | 8 | 8 | 9 | 8 | 8 | 8 |
| Django | Python | 2000 | 9 | 10 | 10 | 10 | 8 | 9 | 9 |
| Hanami | Ruby | 2000 | 7 | 7 | 7 | 7 | 7 | 8 | 7 |
| Rails | Ruby | 1900 | 10 | 10 | 10 | 9 | 8 | 8 | 9 |
| Laravel | PHP | 1000 | 9 | 9 | 10 | 10 | 8 | 8 | 9 |
| Symfony | PHP | 900 | 8 | 9 | 9 | 9 | 9 | 9 | 9 |
При выборе фреймворка следует учитывать все эти факторы в контексте конкретного проекта. Например:
| MAU (10^n) | DAU | RPS | Серверы (Fiber) | Серверы (Django) |
|---|---|---|---|---|
| 10000 (10^4) | 3 500 | 0.61 | 1 | 1 |
| 100000 (10^5) | 35 000 | 6.08 | 1 | 1 |
| 1000000 (10^6) | 350 000 | 60.76 | 1 | 1 |
| 10000000 (10^7) | 3 500 000 | 607.64 | 1 | 1 |
| 100000000 (10^8) | 35 000 000 | 6076.39 | 1 | 4 |
| 1000000000 (10^9) | 350 000 000 | 60763.89 | 2 | 31 |

Согласованное хеширование (Consistent hashing) — это специальная техника хеширования в компьютерных науках, которая обладает важным свойством: при изменении размера хеш-таблицы требуется перераспределить в среднем только n/m ключей, где n — количество ключей, а m — количество слотов.
Согласованное хеширование широко используется в распределенных системах, особенно в:
Согласованное хеширование стало ключевой технологией для многих современных распределенных систем, обеспечивая эффективное распределение данных и нагрузки
Рандеву-хеширование (Rendezvous hashing) или хеширование с наибольшим случайным весом (HRW) — это алгоритм, позволяющий клиентам достичь распределенного соглашения о выборе k вариантов из n возможных. Этот метод часто применяется в распределенных системах для назначения объектов серверам или прокси.
Рандеву-хеширование используется во многих реальных системах, включая:
Рандеву-хеширование становится все более популярным в современных распределенных системах благодаря своей простоте, эффективности и гибкости
| Характеристика | Согласованное хеширование | Рандеву-хеширование |
|---|---|---|
| Год изобретения | 1997 | 1996 |
| Сложность | Более сложный | Проще |
| Метод отображения | Отображает узлы и ключи на кольцо хеширования | Вычисляет хеш-значения для каждой пары ключ-узел |
| Размещение объектов | По часовой стрелке на хеш-кольце | Выбирает узел с наибольшим хеш-значением |
| Балансировка нагрузки | Хорошая, но могут быть горячие точки | В целом лучше, более равномерная |
| Масштабируемость | Хорошо масштабируется при инкрементных изменениях | Менее масштабируемо, пересчитывает все хеши |
| Предварительные вычисления токенов | Требует предварительного вычисления и хранения токенов | Не требует предварительных вычислений токенов |
| Сложность добавления/удаления узлов | O(K/N + log N) | O(n) для базовой реализации |
| Перераспределение ключей | Минимальное перемещение ключей | Объекты перераспределяются на оставшиеся узлы |
| Реальное использование | Cassandra, Couchbase | GitHub Load Balancer, Apache Ignite, Twitter EventBus |

| База данных | CAP | QPS | Масштабирование | Оптимизация | In memory/Disk based | Область применения |
|---|---|---|---|---|---|---|
| Apache Cassandra | AP | До 1 000 000 | Горизонтальное | Write | Disk based | Большие данные, IoT |
| Memcached | CP | До 1 000 000 | Горизонтальное | Read | In memory | Кэширование, веб-приложения |
| Redis | CP | До 500 000+ | Горизонтальное | Read/Write | In memory | Кэширование, сессии |
| Amazon DynamoDB | AP | До 500 000 | Автоматическое горизонтальное | Read/Write | Disk based | Веб-приложения, мобильные приложения |
| ClickHouse | CP | До 300 000 | Горизонтальное | Read/Write | Disk based | Аналитика, большие данные |
| Couchbase | AP | До 200 000 | Горизонтальное | Read/Write | Hybrid | Веб-приложения, мобильные приложения |
| PostgreSQL | CA | До 150 000 | Вертикальное, репликация | Read | Disk based | Транзакционные системы, ГИС |
| Oracle Database | CA | До 120 000 | Вертикальное, RAC кластеры | Read/Write | Disk based | Корпоративные приложения, финансы |
| MongoDB | CP | До 100 000 | Горизонтальное и вертикальное | Read/Write | Disk based | Веб-приложения, IoT |
| MySQL | CA | До 100 000 | Вертикальное, репликация | Read | Disk based | Веб-сайты, CMS |
| Etcd | CP | До 80 000 | Горизонтальное | Read | Disk based | Распределенные системы, конфигурации |
| Apache HBase | CP | До 30 000 | Горизонтальное | Write | Disk based | Большие данные, аналитика |
| Microsoft Azure Cosmos DB | AP | Варьируется | Горизонтальное | Read/Write | Disk based | Глобально распределенные приложения |
| InfluxDB | CP | Варьируется | Горизонтальное | Read/Write | Disk based | IoT, мониторинг |
| PostGIS | CA | Варьируется | Вертикальное, репликация | Read | Disk based | ГИС, картография |
| Apache Spark SQL | CP | Варьируется | Горизонтальное | Read/Write | In memory | Аналитика больших данных |
| OpenSearch | AP | Варьируется | Горизонтальное | Read | Disk based | Поиск, логи |
| CouchDB | AP | Варьируется | Горизонтальное | Read/Write | Disk based | Веб-приложения, мобильные приложения |
| Firebird | CA | Варьируется | Вертикальное, репликация | Read/Write | Disk based | Встраиваемые системы, локальные приложения |
Примечания:

Выбор правильной архитектуры = Выбор правильных сражений + Управление компромиссами
Перевод: https://gist.github.com/vasanthk/485d1c25737e8e72759f
Балансировка нагрузки помогает масштабироваться горизонтально на постоянно растущем числе серверов, но кэширование позволит вам гораздо эффективнее использовать уже имеющиеся ресурсы, а также сделает возможными иначе недостижимые требования к продукту.
Примеры:
Публичные серверы масштабируемого веб-сервиса скрыты за балансировщиком нагрузки. Этот балансировщик нагрузки равномерно распределяет нагрузку (запросы от ваших пользователей) на вашу группу/кластер серверов приложений.
Типы:
Репликация базы данных — это частое электронное копирование данных из базы данных на одном компьютере или сервере в базу данных на другом, чтобы все пользователи имели доступ к одному уровню информации. Результатом является распределенная база данных, в которой пользователи могут получить доступ к данным, относящимся к их задачам, не мешая работе других. Реализация репликации базы данных с целью устранения неоднозначности или несогласованности данных между пользователями известна как нормализация.
Партиционирование реляционных данных обычно относится к разложению ваших таблиц либо по строкам (горизонтально), либо по столбцам (вертикально).
Для достаточно небольших систем вы часто можете обойтись специальными запросами к SQL-базе данных, но этот подход может не масштабироваться тривиально, когда количество хранимых данных или нагрузка на запись требует шардинга вашей базы данных, и обычно требует выделенных подчиненных узлов для выполнения этих запросов (в этот момент, возможно, вы предпочтете использовать систему, разработанную для анализа больших объемов данных, вместо борьбы с вашей базой данных).
Добавление слоя map-reduce позволяет выполнять интенсивные операции с данными и/или обработкой за разумное время. Вы можете использовать его для расчета предлагаемых пользователей в социальном графе или для создания аналитических отчетов. Например, Hadoop, и, возможно, Hive или HBase.
Разделение платформы и веб-приложения позволяет масштабировать части независимо. Если вы добавляете новый API, вы можете добавить серверы платформы без добавления ненужной мощности для уровня веб-приложения.
Добавление платформенного слоя может быть способом повторного использования вашей инфраструктуры для нескольких продуктов или интерфейсов (веб-приложение, API, приложение для iPhone и т.д.) без написания слишком большого количества избыточного шаблонного кода для работы с кэшами, базами данных и т.д.

Перевод репозитория https://leetcode.com/discuss/career/229177/My-System-Design-Template
a) DNS
b) CDN [Push vs Pull]
c) Балансировщики нагрузки [Активный-Пассивный, Активный-Активный, Уровень 4, Уровень 7]
d) Обратный прокси
e) Масштабирование уровня приложений [Микросервисы, Обнаружение сервисов]
f) БД [RDBMS, NoSQL]
g) Кэши
h) Асинхронность
i) Коммуникация

Эти цифры показывают, насколько критична оптимизация работы с памятью и дисками для производительности программ.
Понимание сетевых задержек важно при разработке распределенных систем.
Эти цифры помогают оценивать эффективность различных операций в коде.
Разработчикам также полезно помнить степени двойки: 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024[31]. Они часто встречаются при работе с памятью, файловыми системами и другими аспектами разработки.

Перевод и адаптация этого репозитория https://github.com/jguamie/system-design/blob/master/notes/system-design-outline.md
Это рекомендуемый подход к решению задач проектирования систем. Не все эти темы будут актуальны для конкретной задачи.

| Этап | Вопросы | Примеры ответов |
|---|---|---|
| Уточнение требований | Какие основные функции должна выполнять система? | Система должна позволять пользователям загружать видео, просматривать их и оставлять комментарии |
| Сколько пользователей будет у системы? | Ожидается около 10 миллионов активных пользователей в месяц | |
| Какой ожидается рост пользовательской базы? | Прогнозируется рост на 20% ежегодно в течение следующих 3 лет | |
| Какие основные сценарии использования системы? | Загрузка видео, просмотр видео, поиск видео, комментирование | |
| Определение масштаба | Какой ожидаемый объем данных? | Ожидается хранение около 500 ТБ видео и 50 ГБ метаданных |
| Какое соотношение операций чтения к записи? | Ожидается соотношение 100:1 чтения к записи | |
| Какая ожидаемая пиковая нагрузка на систему? | До 100 000 запросов в секунду в пиковые часы | |
| Определение API | Какие основные API endpoints нужны? | /upload, /view, /search, /comment |
| Какие параметры будут у этих API? | /view?video_id=123, /search?query=cats | |
| Проектирование данных | Какая структура данных подойдет для хранения видео? | Объектное хранилище для видеофайлов, реляционная БД для метаданных |
| Как организовать индексирование для быстрого поиска? | Инвертированный индекс по ключевым словам и тегам видео | |
| Масштабирование | Как обеспечить высокую доступность системы? | Репликация данных, распределение по нескольким дата-центрам |
| Как оптимизировать доставку контента пользователям? | Использование CDN для кэширования популярных видео | |
| Как масштабировать обработку загрузки видео? | Асинхронная обработка через очереди сообщений | |
| Дополнительные вопросы | Как обеспечить безопасность системы? | Шифрование данных, аутентификация пользователей, ограничение доступа |
| Как организовать мониторинг системы? | Сбор метрик производительности, логирование ошибок, алерты |