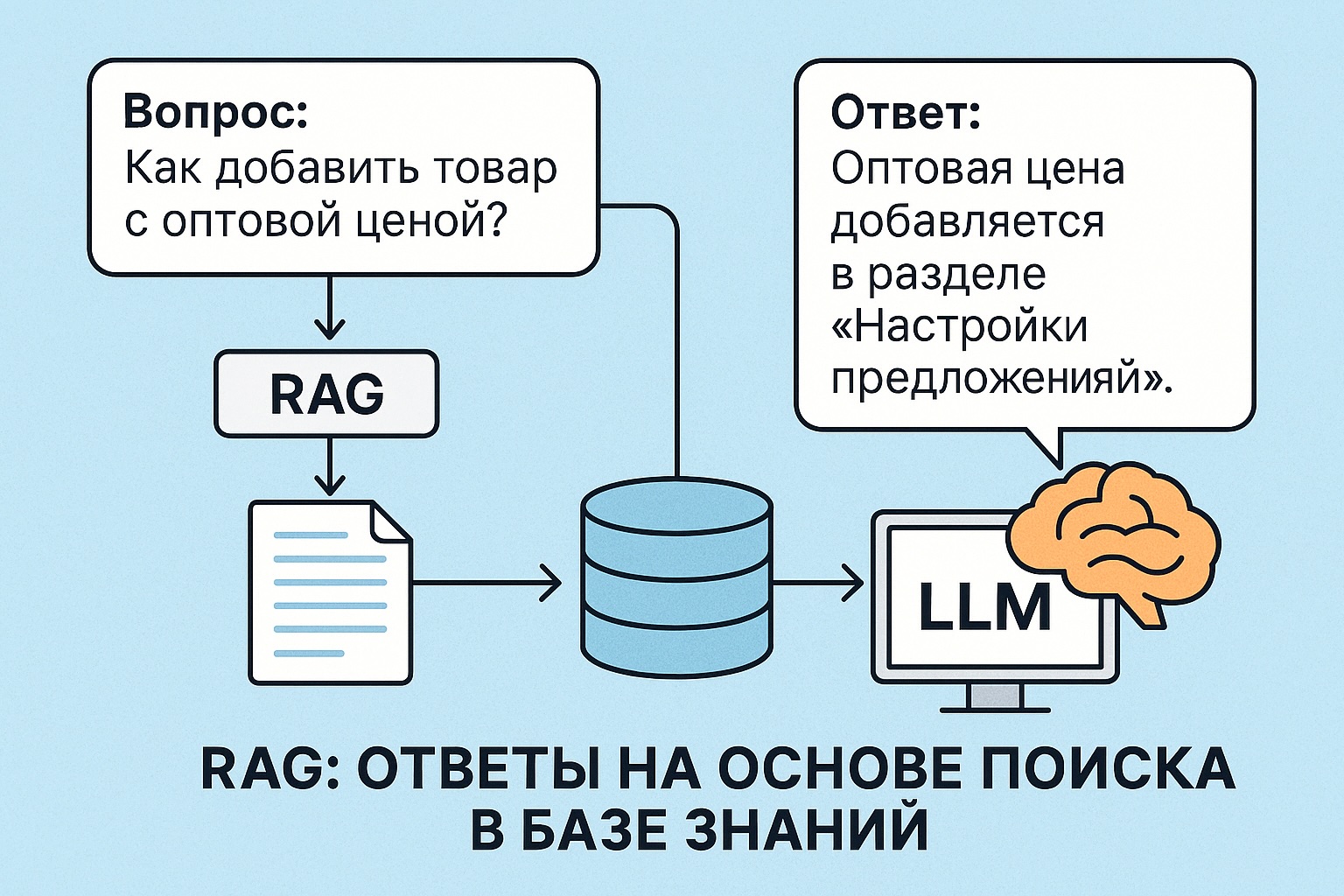
RAG (Retrieval-Augmented Generation) — это подход, при котором большая языковая модель (LLM) получает не только сам вопрос, но и дополнительную информацию из базы знаний. Модель не «вспоминает» ответ из своей памяти, а «читает» найденный текст и отвечает на основе него.
Зачем нужен RAG
LLM не знает ничего о ваших внутренних документах, продуктах или инструкциях. Она может галлюцинировать — выдумывать ответы.
RAG позволяет использовать актуальные и точные данные:
- Вы передаёте в модель текст, найденный по запросу
- Модель отвечает с опорой на этот текст
Как работает RAG
- Получаем вопрос от пользователя
- Кодируем его в вектор (эмбеддинг)
- Ищем похожие документы в базе (векторный поиск)
- Склеиваем найденные тексты и добавляем к вопросу
- Передаём всё это в LLM как prompt
- Модель отвечает
Что нужно для RAG
- Модель для эмбеддингов — например,
sentence-transformers - Векторное хранилище — например,
faiss,qdrant,weaviate,pinecone - LLM — любая модель генерации, например Mistral, LLaMA, GPT
Пример на Python (faiss + sentence-transformers)
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# База документов
docs = [
"Товар добавляется через Личный кабинет в разделе Каталог.",
"Оптовые цены указываются отдельно от розничных.",
"Поддержка работает с 10:00 до 18:00 по будням."
]
# Эмбеддер
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(docs)
# Векторный индекс
index = faiss.IndexFlatL2(embeddings[0].shape[0])
index.add(np.array(embeddings))
# Запрос
query = "Как задать оптовую цену?"
query_embedding = model.encode([query])
_, I = index.search(query_embedding, k=1)
# Результат
context = docs[I[0][0]]
print("Контекст:", context)Теперь можно собрать prompt:
prompt = f"Инструкция: {context}\n\nВопрос: {query}\nОтвет:"Передаём этот prompt в LLM (через transformers, vllm, OpenAI API и т. д.)
Преимущества RAG
- Актуальность — ответы можно обновлять без переобучения модели
- Контроль — вы точно знаете, откуда берётся информация
- Гибкость — можно подключить любые источники: статьи, документы, БД
Вывод
RAG — мощный способ комбинировать знания вашей системы с генеративной силой LLM. Это основа умных ассистентов, корпоративных поисковиков и сервисов поддержки, которые действительно отвечают по делу.