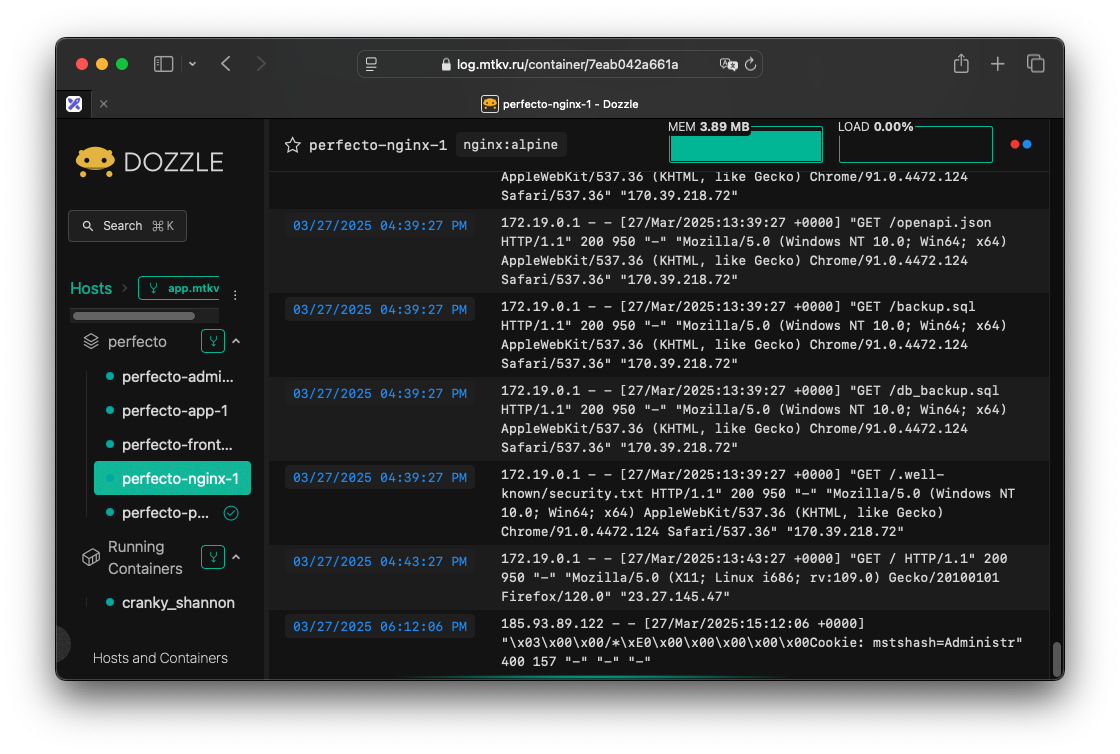
Все мы любим красивые логи, которые нам дают ребята из Платформы, где все понятно и хорошо видно. Но что делать со своими pet-проектами? Когда они уже в мини-продакшине, как посмотреть что творится в контейнере?
Раньше я ходил через ssh, подключался интерактивно к контейнеру, смотрел в реальном времени логи, пока не обнаружил шикарный Dozzle!
Всего одна команда и один конфигурационный файл, и вот у вас почти что свой Docker Desktop со всеми контейнерами и всеми логами в реальном времени!
docker run --restart always -d -v /var/run/docker.sock:/var/run/docker.sock -v /data:/data -p 8080:8080 amir20/dozzle --auth-provider simpleи создать перед этим файл в /data/users.yml
users:
# "admin" here is username
admin:
email: me@email.net
name: Admin
# Generate with docker run amir20/dozzle generate --name Admin --email me@email.net --password secret admin
password: $2a$11$9ho4vY2LdJ/WBopFcsAS0uORC0x2vuFHQgT/yBqZyzclhHsoaIkzK
filter:Вот что получаем в итоге:
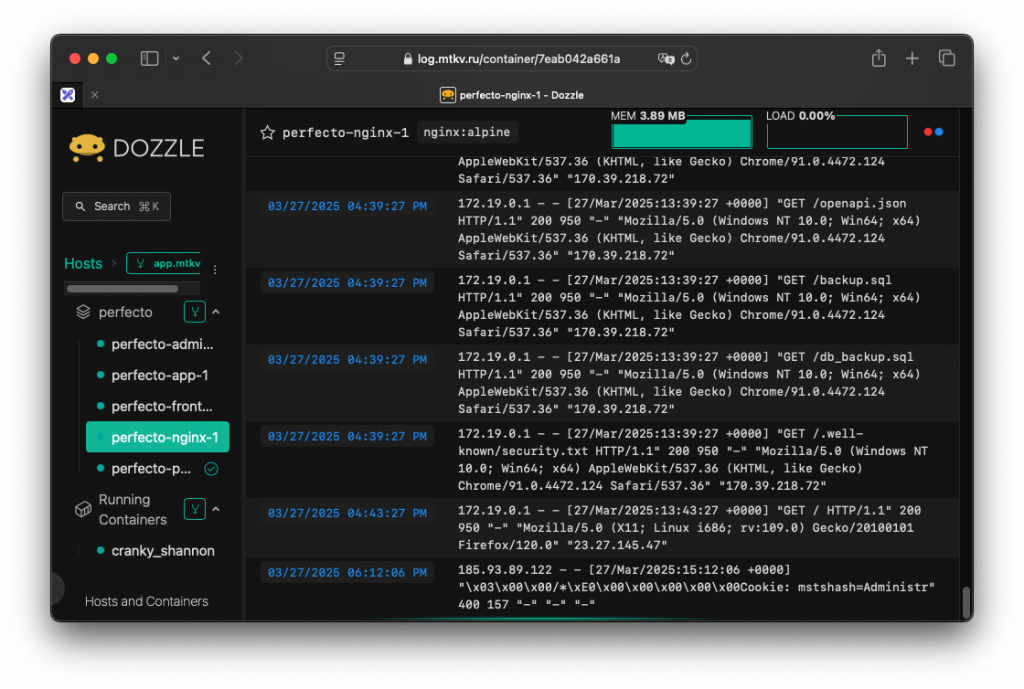
Доступ к любому контейнеру и его логам. Все это можно через Caddy Server повесить на удобный вам поддомен и в реальном времени смотреть на то как работает ваш сайт. Или не работает, и узнать почему.