-

Как работает MCP: внешний разум для вашей LLM
Когда мы говорим о современных языковых моделях вроде GPT или Claude, легко забыть, что всё, что они знают — это текст, который они когда-то прочитали. А значит, всё, чего они не знают, остаётся за пределами их внимания. И вот тут появляется MCP — Model Context Protocol. Это способ «расширить сознание» модели, подключив её к живым данным, инструментам и действиям.
Эта статья отвечает на важные вопросы, которые возникают, когда ты впервые сталкиваешься с MCP:
- Что именно он делает?
- Чем он отличается от API?
- Как модель узнаёт, какие инструменты есть?
- Где лежат адреса, авторизация и прочее?
- Можно ли через MCP совершать не только запросы, но и действия?
MCP на пальцах: таблица-пример
Для начала — суть в одной таблице:
Пример запроса Как и через что AI обращается Источник ответа или действия “Что такое квантовая запутанность?” Внутренние знания модели Параметры самой LLM “Что случилось в Иране сегодня?” Вызов через веб-поиск, API или плагин Интернет “Сколько заказов мы сделали в марте?” Вызов sql_query через MCP Внутренняя база данных “Найди договор, где срок подписания — июль 2023” Векторный поиск через MCP-инструмент vector_search Ваша база документов “Построй график продаж за год” Последовательность: sql_query → plot_data Комбинация базы и визуализатора “Выполни расчёт по Excel-файлу” Сначала file_extract, затем code_execute через MCP Excel-файл или его копия “Отправь СМС клиенту” Вызов инструмента send_sms с номером и текстом Внешний сервис сообщений (например, Twilio) Что делает MCP на самом деле
С технической точки зрения, MCP — это протокол общения между LLM и внешними источниками данных или действиями. Он описывает, как модель может:
- обратиться к SQL-базе;
- извлечь файл;
- вызвать API;
- отправить сообщение;
- выполнить код;
- и даже скомбинировать несколько действий последовательно.
Главная идея: модель не знает, как устроен внешний мир, но умеет формировать запросы в едином формате, а MCP-сервер знает, как их обработать и что вернуть обратно.
MCP — это не просто API
Сразу возникает логичный вопрос: а чем MCP отличается от обычного API?
Ответ: уровнем абстракции.
Обычный API — это конкретная реализация с конкретной документацией.
MCP — это унифицированный способ описания и исполнения любых API. Вся магия MCP в том, что:
- Модель видит инструмент как «псевдофункцию» с описанием.
- MCP-сервер сам знает, как эту функцию реализовать.
- Протокол позволяет строить последовательности действий (например, “спроси в базе — потом построй график”).
А как модель знает, какие есть инструменты?
Модель не «знает» заранее. При старте сессии или при подключении плагина ей передаётся так называемый Tool Manifest — описание всех доступных инструментов. Обычно это JSON, в котором указано:
- название инструмента (send_sms, sql_query);
- описание;
- параметры и их типы.
Пример:
{
«name»: «send_sms»,
«description»: «Sends an SMS to the specified phone number»,
«parameters»: {
«number»: «string»,
«text»: «string»
}
}
Модель читает этот список и потом сама решает, какой инструмент использовать и какие параметры подставить.
А как она узнаёт, где находится MCP-сервер?
Вот тут кроется то, чего пока не хватает в большинстве реализаций: механизма подключения MCP-серверов.
У OpenAI есть .well-known/ai-plugin.json. У Anthropic — tool-use manifest. У LangChain — ToolLoader.
У MCP должен быть публичный манифест MCP-сервера, в котором указано:
- mcp_url — куда слать запросы;
- auth — какая авторизация нужна (Bearer, API Key, OAuth);
- tools_manifest_url — где взять список инструментов.
То есть подключение MCP-сервера должно выглядеть примерно так:
{
«name»: «Internal Tools MCP»,
«mcp_url»: «https://mcp.mycompany.com/api»,
«auth»: {
«type»: «bearer»,
«token»: «sk-xyz»
},
«tools_manifest_url»: «https://mcp.mycompany.com/api/tools»
}
Пока нет единого глобального репозитория MCP-серверов, но такая идея витает в воздухе — и обязательно появится.
А можно ли через MCP не просто получать данные, а делать что-то?
Да. И это один из самых важных и недооценённых аспектов.
Пример — отправка СМС. Модель не знает, что такое Twilio, какие там нужны ключи, заголовки и URL. Она просто вызывает send_sms с нужными параметрами. А дальше:
- MCP-сервер подставляет токен.
- Отправляет POST-запрос на нужный адрес.
- Возвращает модели { «status»: «sent» }.
Модель как бы управляет миром — через интерфейс MCP.
Вывод
MCP — это мост между языковой моделью и реальным миром.
Он не заменяет API, он делает их доступными, понятными и управляемыми для моделей. MCP позволяет строить LLM-агентов, которые не просто болтают, а действуют, получают доступ к данным, комбинируют инструменты и работают в рамках заданной архитектуры.
Если раньше вы ограничивались ответами из головы модели — теперь можно подключить к ней всё, что у вас есть: от баз до внешних сервисов, от PDF до внутренних CRM. И всё это — в едином протоколе.
-

Как я писал MVP с AI-ассистентами: опыт, грабли и тактика
Недавно я делал мобильное приложение на Flutter, с FastAPI на бэкенде и Streamlit для административной панели. Всё это — в рамках подхода “AI-first”, когда почти весь код пишется с помощью копайлот-ассистентов: Gemini, ChatGPT, Claude.
И вот что я понял из такого долгосрочного программирования…
Умные, но забывчивые
Современные копайлот-ассистенты — это не команда, а стажёры. Они пишут быстро, но:
- забывают, что делали в предыдущем файле;
- не держат в голове структуру проекта;
- путаются, если вы перескакиваете между фронтом, мобилкой и бэком.
Мораль: не стоит надеяться, что AI вспомнит, как вы называли переменную три дня назад в другом микросервисе. Но выход есть.
(далее…) -

Как настроить мультиязычную встречу в Google Meet с автопереводом
Команды становятся всё более интернациональными — участники говорят на английском, русском, французском, испанском и даже китайском. Но как провести созвон, если не все владеют одним общим языком? Удивительно, но Google Meet уже умеет помогать в таких ситуациях: автоматически распознавать речь и переводить её в субтитры.
Звучит как магия, и — спойлер — работает это действительно хорошо. Особенно если на встрече используется два языка. Когда больше — потребуется чуть больше внимания к настройке, но и это вполне реально.
Что нужно для работы
Google Meet умеет автоперевод только в платных версиях (Google Workspace Business/Enterprise). Также потребуется:
- компьютер (на мобильных устройствах есть ограничения),
- браузер Google Chrome (он самый стабильный для этой функции),
- и немного терпения на начальной настройке.
-

Эпохи и переобучение: как понять, когда модель уже научилась
При обучении моделей машинного обучения часто возникает вопрос: сколько эпох нужно? Когда модель уже «поняла» данные, а когда она начинает запоминать их слишком точно (то есть переобучаться)?
В этой статье:
- Что такое эпоха
- Как понять, что модель переобучается
- Сколько эпох нужно
- Как выбрать и настроить обучение правильно
Что такое эпоха
Эпоха — это один полный проход по всему обучающему набору данных.
Допустим, у вас есть 10 000 примеров, и вы обучаете модель с
batch_size=100. Это значит, за одну эпоху модель увидит все примеры по 100 штук за раз — всего 100 шагов.Когда эпох несколько, модель повторно видит одни и те же данные, чтобы «отточить» предсказания.
(далее…) -

Обзор методов квантования языковых моделей: GPTQ, GGUF, QLoRA
Большие языковые модели (LLM) часто требуют десятки гигабайт видеопамяти и мощные серверы для запуска и обучения. Квантование — это способ уменьшить объём модели и ускорить её работу, с минимальной потерей качества.
В этой статье:
- Что такое квантование
- Какие есть методы: GPTQ, GGUF, QLoRA
- Чем они отличаются
- Когда и как их применять
Что такое квантование
Квантование — это перевод весов модели из 32-битного формата (
float32) в более компактные форматы:float16,int8,int4и т. д.Цель:
- уменьшить размер модели (в 2–8 раз)
- сократить использование VRAM
- ускорить инференс
Пример: модель в
(далее…)fp32весит 13 ГБ, а вint4— 3–4 ГБ. -
Базовая инфраструктура для запуска LLM: Triton, ONNX, TorchScript и другие
Когда модель готова, важно не только её обучить, но и запустить эффективно, особенно если она используется в проде. Большие языковые модели (LLM) требуют особого подхода к инференсу — и тут приходят на помощь оптимизированные форматы и инференс-серверы.
Что нужно для продакшен-инференса
- Высокая скорость обработки запросов
- Эффективное использование GPU
- Поддержка большого числа одновременных пользователей
- Гибкость и переносимость модели
Обычный
(далее…)pipeline()из Hugging Face удобен, но не масштабируется. Для продакшена нужны другие инструменты. -

Метрики оценки качества моделей
Когда вы обучаете или используете модели машинного обучения и большие языковые модели (LLM), важно измерять их качество. Без метрик невозможно понять, стала ли модель лучше, хуже или осталась такой же.
В этой статье мы рассмотрим:
- Метрики для классификации
- Метрики для генерации текста
- Специальные бенчмарки для LLM
- Как и когда их применять
Классификация: accuracy, F1 и другие
Если модель должна выбрать правильный вариант ответа (например, категорию объявления), используются классические метрики:
- Accuracy — доля правильных ответов
- Precision — точность (насколько предсказанные метки действительно верные)
- Recall — полнота (насколько хорошо модель нашла все правильные ответы)
- F1-score — среднее между precision и recall
-
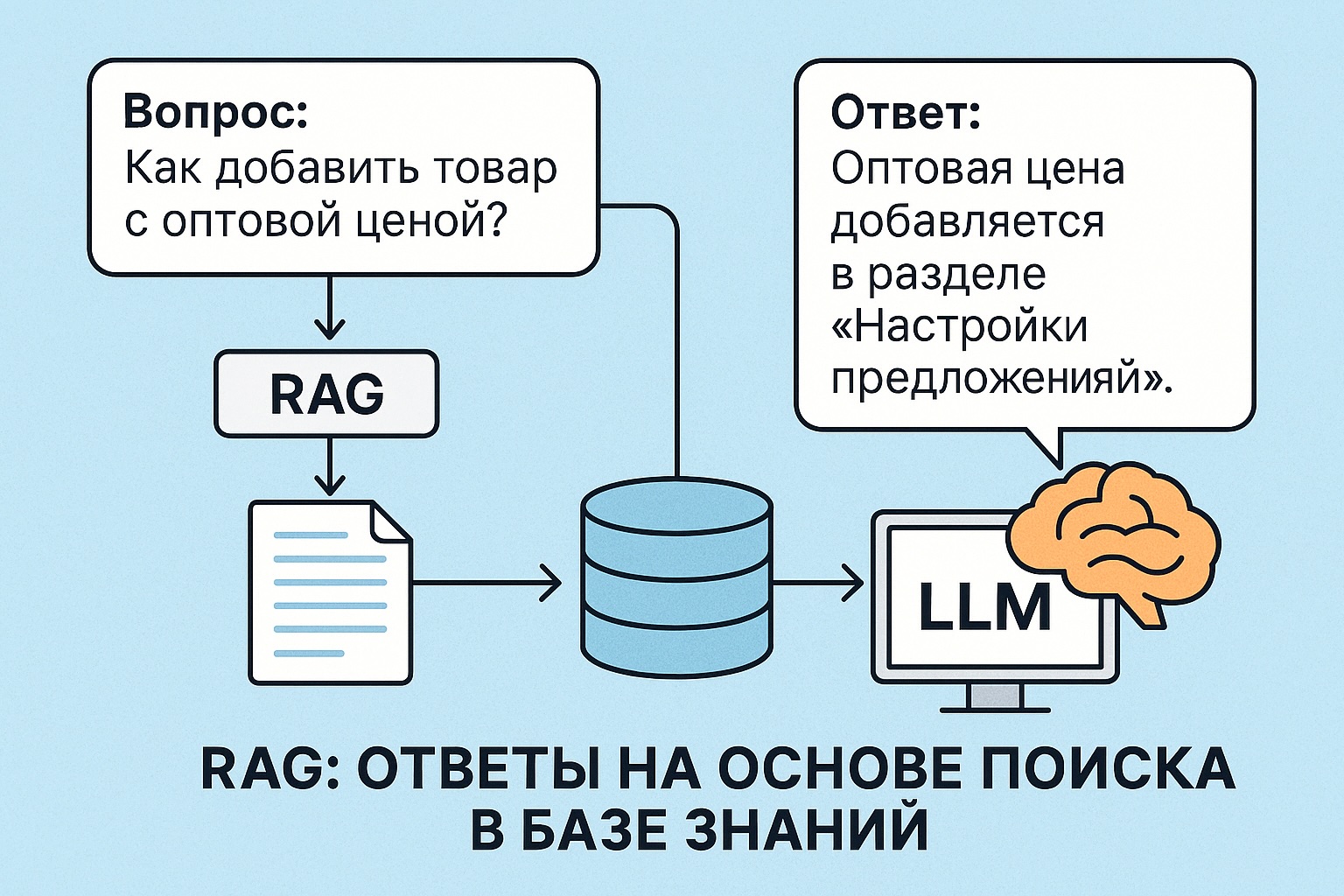
RAG: Ответы на основе поиска в базе знаний
RAG (Retrieval-Augmented Generation) — это подход, при котором большая языковая модель (LLM) получает не только сам вопрос, но и дополнительную информацию из базы знаний. Модель не «вспоминает» ответ из своей памяти, а «читает» найденный текст и отвечает на основе него.
Зачем нужен RAG
LLM не знает ничего о ваших внутренних документах, продуктах или инструкциях. Она может галлюцинировать — выдумывать ответы.
RAG позволяет использовать актуальные и точные данные:
- Вы передаёте в модель текст, найденный по запросу
- Модель отвечает с опорой на этот текст
Как работает RAG
- Получаем вопрос от пользователя
- Кодируем его в вектор (эмбеддинг)
- Ищем похожие документы в базе (векторный поиск)
- Склеиваем найденные тексты и добавляем к вопросу
- Передаём всё это в LLM как prompt
- Модель отвечает
-

Трекинг экспериментов с MLflow и DVC
При разработке моделей важно не только обучить модель, но и уметь:
- отслеживать параметры обучения
- сохранять метрики (точность, F1 и др.)
- версионировать модели и датасеты
- воспроизводить эксперименты
Для этого используются инструменты вроде MLflow и DVC.
Зачем нужен трекинг
Допустим, вы обучили три модели с разными параметрами. Какая из них лучше? Сколько эпох было? Какой
learning_rate? Где лежит файл модели?Без трекинга это всё теряется в коде и папках. С трекингом — у вас есть история всех запусков и чёткая структура.
(далее…) -
Обучение больших моделей с помощью QLoRA
QLoRA — это метод, который позволяет дообучать большие языковые модели (LLM) в сжатом 4-битном виде, экономя память и ресурсы. Он позволяет запускать fine-tuning даже на одной видеокарте вроде RTX 3060 или 3090.
В этой статье разберёмся:
- Что такое QLoRA
- Как она работает
- Когда и зачем её использовать
- Как на практике дообучить свою модель с помощью QLoRA
Что такое QLoRA
QLoRA (Quantized LoRA) сочетает два подхода:
- Квантование — уменьшает размер модели, переводя её веса в 4-битный формат (вместо 16 или 32 бит)
- LoRA (Low-Rank Adapters) — позволяет добавлять к модели небольшие обучаемые адаптеры, не изменяя сами веса модели
Денис Матаков
Блог технического руководителя